Star Schema Modellierung für Power BI und Data Warehouses
Star Schema Modellierung teilt Daten in Fakten und Dimensionen ein, um die beste Leistung in Berichtsabfragen z.B. in Power BI zu erreichen.

Star Schema Modellierung teilt Daten in Fakten und Dimensionen ein, um die beste Leistung in Berichtsabfragen z.B. in Power BI zu erreichen.
In der heutigen datengetriebenen Welt kommt kaum noch ein Unternehmen ohne leistungsstarke Analysen und Berichten aus. Ein Data Warehouse (DWH) bildet dabei die zentrale Komponente, um Daten aus verschiedenen Quellen zu integrieren und für Business Intelligence (BI) über Reporting-Tools wie Power BI, Tableau, Excel, SAP Analytics, Microstrategy usw. verfügbar zu machen. Im Zentrum eines optimal gestalteten Data Warehouses steht häufig das Starschema – ein schlankes, leicht verständliches Datenmodell, das schnelle Abfragen ermöglicht und die Datenanalyse nachhaltig vereinfacht.
In diesem Artikel erfahren Sie:
Welche Vorteile das Starschema bietet und wie es sich vom Snowflake Schema unterscheidet
Wie ETL- und ELT-Prozesse zum Aufbau eines leistungsstarken Data Warehouses beitragen
Warum Slowly Changing Dimensions (SCD) für historische Daten relevant sind
Wie Data Vault als Methode eine flexible Alternative zum klassischen Starschema bietet
Immer mehr Unternehmen möchten ihre Daten für vorausschauende Analysen nutzen. Durch ein Data Warehouse werden diese Daten aus unterschiedlichen Systemen extrahiert, bereinigt und in einer leistungsstarken Datenbank zusammengeführt. Dieser Prozess wird auch ETL (Extract-Load-Transform) genannt. So können historische und aktuelle Informationen kombiniert und langfristig analysiert werden.
Der wesentliche Unterschied zwischen einem Data Warehouse und einer operativen Datenbank (z. B. in einem CRM) besteht darin, dass operative Systeme vor allem Transaktionen im Tagesgeschäft (OLTP) abwickeln, während ein Data Warehouse für die Analyse historischer Daten (OLAP) ausgelegt ist.
Reporting-Tools wie Power BI sind auf Starschema bzw. Sternmodellierung ausgelegt, um die beste Berichtsleistung und kurze Ladezeiten der Abfragen zu erreichen.
Das Starschema ist ein etabliertes Datenmodell für Data Warehouses und verdankt seinen Namen der sternförmigen Struktur. In der Faktentabelle (Zentrum des Sterns) werden sämtliche Ereignisse, Kennzahlen oder Beobachtungen gespeichert. Die Dimensionstabellen (die „Strahlen“ des Sterns) beschreiben die Kontexte dieser Fakten, zum Beispiel Kunden, Produkte oder Zeiträume.
Diese Anordnung bietet verschiedene Vorteile:
Einfache Struktur : Dank der klaren Aufteilung in Fakten- und Dimensionstabellen ist das Modell leicht verständlich.
Schnelle Abfragen : Da das Starschema häufig denormalisiert ist, können Abfragen sehr performant ausgeführt werden.
Geringer Entwicklungsaufwand : Der Aufbau eines Data Warehouses mit Starschema ist überschaubar und lässt sich gut pflegen.
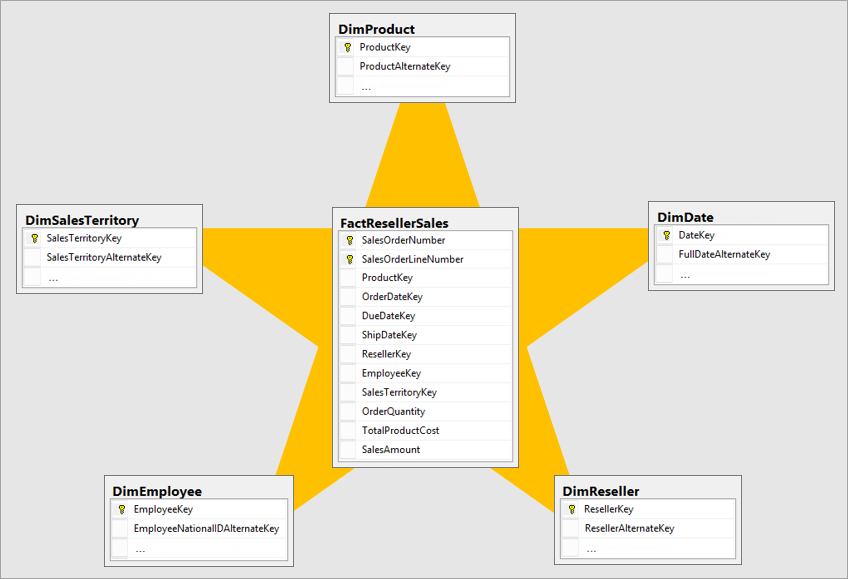
Dimensionstabellen enthalten deduplizierte Werte und einen eindeutigen Schlüssel – beispielsweise eine Liste von Produkten mit Produktnamen und Produktnummer. In Power BI empfiehlt es sich zudem, numerische Index-Schlüssel (z. B. Integer-IDs) in den Faktentabellen zu verwenden, da diese von der VertiPaq Engine besonders effizient verarbeitet werden und somit für schnellere Abfragen sorgen. Die Sternstruktur verdeutlicht, dass ein einzelnes Dimensionselement (z. B. ein bestimmtes Produkt) mehrere Faktzeilen gleichzeitig filtern kann.
Beim Snowflake Schema werden die Dimensionen weiter in zusätzliche Tabellen (sogenannte Lookup-Tabellen) aufgespalten, um eine höhere Normalisierung (bis zu 3NF) zu erreichen. Dadurch reduzieren sich Redundanzen und Speicherbedarf, jedoch steigt die Komplexität. Das Starschema ist demgegenüber einfacher, da es auf einer denormalisierten Struktur basiert, aber mehr Speicherplatz beanspruchen kann.
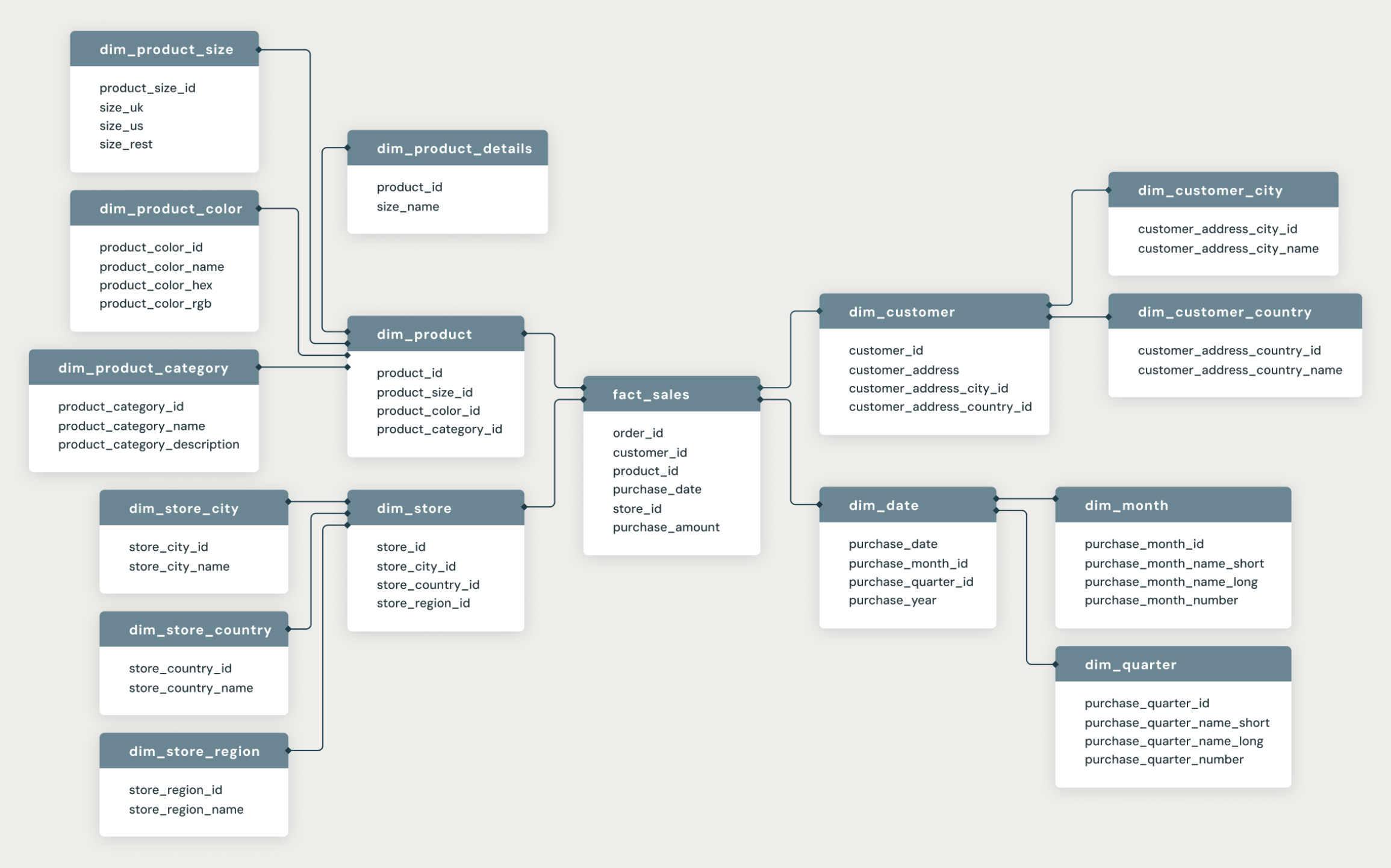
Nachdem entschieden ist, ob ein Starschema oder Snowflake Schema verwendet wird, erfolgt die Datenintegration ins Data Warehouse. Dabei kommen zwei grundlegende Prozessketten zum Einsatz: ELT und ETL . Beide umfassen drei Hauptschritte:
Extract : Daten aus verschiedensten Quellen (z. B. ERP, CRM, Datenbanken) extrahieren.
Transform : Daten bereinigen, validieren und in das gewünschte Zielformat bringen.
Load : Daten ins DWH laden, um sie später mit BI-Software (z. B. Power BI) auszuwerten.
Beim ELT-Ansatz werden die Rohdaten zuerst in einen Staging-Bereich innerhalb des Data Warehouses geladen und anschließend transformiert. Die Rohdaten bleiben dadurch erhalten, was für eine nachträgliche Anpassung von Transformationsregeln oder eine flexible Datenanalyse vorteilhaft ist.
Im Gegensatz dazu werden die Daten beim ETL-Ansatz bereits vor dem Laden transformiert. Sensible Informationen, die nicht im DWH landen sollen, lassen sich direkt im Transformationsschritt filtern und entfernen. Diese Methode ist oft schneller in der Analyse, erfordert jedoch eine gründlichere Planung und aufwändigere Entwicklung.
Da Data Warehouses historische Daten langfristig speichern, ist der Umgang mit Slowly Changing Dimensions (SCD) besonders wichtig. Beispiele für SCDs sind Produktpreise oder Kundenadressen, die sich langsam über die Zeit verändern.
SCD1 : Überschreibt alte Werte mit neuen.
SCD2 : Speichert frühere Zustände durch das Hinzufügen neuer Zeilen, beispielsweise mit einem Gültigkeitsflag oder Start- und Enddatum .
Die SCD2-Variante ermöglicht ausführliche Verlaufsanalysen, erhöht aber den Speicherbedarf und erfordert komplexere Updates.
Data Vault ist ein relativ neues Konzept, das besonders für große und komplexe Datenlandschaften entwickelt wurde. Data Vault 2.0 erweitert diese Methodik um Prozesse für Entwicklung, Bereitstellung und Automatisierung. Es setzt auf drei Hauptkomponenten:
Hubs : Enthalten stabile, eindeutige Geschäftsschlüssel, die sich selten ändern.
Links : Stellen Beziehungen (Transaktionen, Zusammensetzungen etc.) zwischen mehreren Hubs her.
Satellites : Speichern Metadaten und zeitliche Informationen zu den Hubs oder Links („Was wussten wir wann?“).
Durch die Trennung von stabilen und variablen Elementen bietet Data Vault eine hohe Agilität und Skalierbarkeit . Insbesondere der Umgang mit SCDs wird vereinfacht, da Änderungen an Dimensionen in separaten Satelliten abgelegt werden.
Ein Starschema bildet einen hervorragenden Ausgangspunkt für den Aufbau eines leistungsfähigen Data Warehouses. Dank seiner einfachen Struktur ermöglicht es schnelle Abfragen und einen leichten Einstieg in die Welt der Datenanalyse . Wer komplexere Anforderungen oder große Datenmengen hat, kann alternativ auf das Snowflake Schema oder moderne Ansätze wie Data Vault zurückgreifen. Wichtig ist eine saubere und durchdachte Datenmodellierung , um aus den gewonnenen Informationen den maximalen Mehrwert zu schöpfen.
Nutzen Sie die Stärken des Starschemas , um Ihr Data Warehouse zu beschleunigen, Ihr Unternehmen datengetrieben zu steuern und langfristig konkurrenzfähig zu bleiben.
Quellen & Weiterführendes:
Wikipedia: Star Schema: https://en.wikipedia.org/wiki/Star_schema
Wikipedia: Snowflake Schema: https://en.wikipedia.org/wiki/Snowflake_schema
Wikipedia: Data Vault Modeling: https://en.wikipedia.org/wiki/Data_vault_modeling
Tipp: Planen Sie die Einführung eines Starschemas sorgfältig, wählen Sie den passenden ETL/ELT-Prozess und berücksichtigen Sie den Umgang mit Slowly Changing Dimensions. Nur so stellen Sie sicher, dass Ihr Data Warehouse auf lange Sicht optimal performt, die referentielle Integrität bewahrt und den gestiegenen Anforderungen an moderne Datenanalysen gerecht wird.