
Picture Source: Tobias Fischer Unsplash
In a world in which data is all over the place, data driven decisions and business intelligence (BI) are not optional anymore, but are essential for any business to succeed. However, in order to use data efficiently, it must be prepared adequately beforehand. In this article, we will give you qualified insights into different types of data models and the process of building a data warehouse (DWH).
Table of contents
DWH Basics
Acquiring data that is needed for analysis is only the first and arguably the simplest step in a BI framework. Data must be cleaned, stored and maintained before connecting it to a BI software like Power BI.This is what data warehouses (DWH) are used for. The main difference between a data warehouse and a Database (DB) is that the latter is mainly used in OLTP (online transaction processing), whereas a DWH is mainly used for OLAP (online analytical processing). Briefly, OLTP systems focus on transactions and day-to-day operations. OLAP systems focus on decision making using historical data. DWHs can be designed using a wide suite of tools e.g., PostgreSQL and MySQL.
Data Models
What is a Star Schema?
Data warehouses are usually designed in a simple form called a star schema. Star schema gained its name, as it consists of two main components: a fact table in the center of the logical diagram of the schema, connected to several dimension tables as shown in the following figure. The fact table is where all the events (facts) are stored. These events can be any observations we want to store in the most granular form. The other component, i.e. dimensions tables, describe the business entities e.g., customers, products or even time.
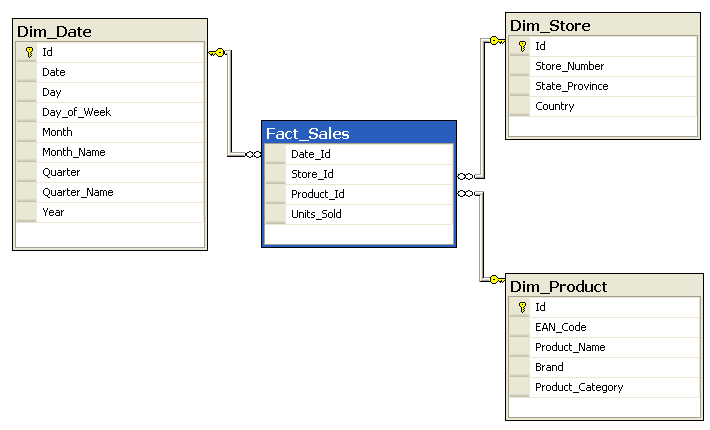
Star Schema vs. Snowflake Schema
Although star schema is simple and fast, for some use cases it’s not the best approach. Accordingly, another well-known approach, the snowflake schema is needed. The difference between these two schemas is that snowflake schema stores data in a normalized form whereas star schema is denormalized. That means instead of saving everything related to a certain dimension in one table only (star schema), snowflake schema splits dimensional tables to further dimensional tables called lookup tables. These can be in turn split up into more tables as can be seen in the next figure. This allows snowflake schema to adhere to the third normal form 3NF. While being more complex and slower than the simple star schema, the snowflake schema requires less space to save data and is less prone to data inconsistency. This can be essential when dealing with enormous amounts of data.
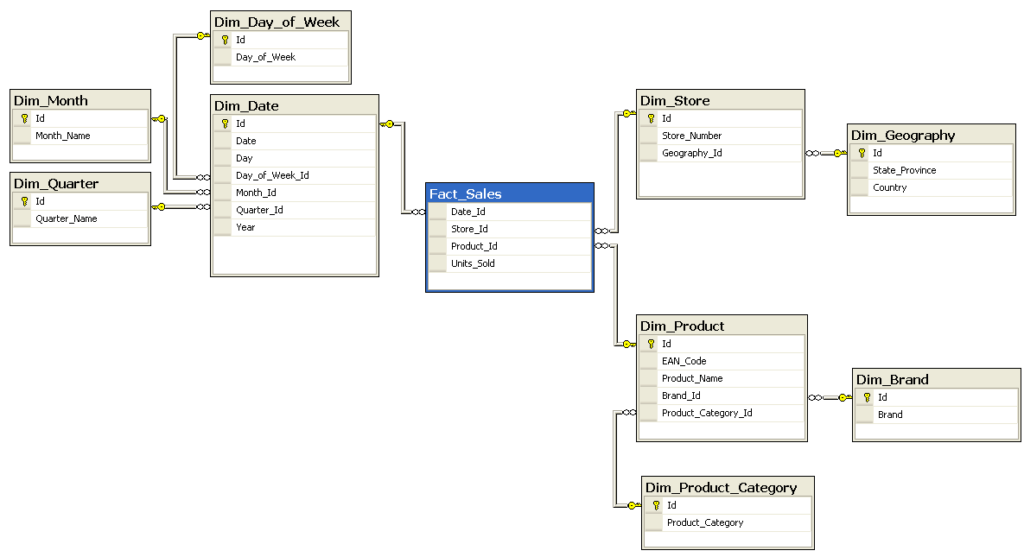
Building a Data Warehouse: ELT/ETL
After choosing the most appropriate schema, the next step is populating the data tables and getting the DWH up and running. For that matter, there are three main tasks to be done: Extract, Load and Transform. Depending on the order of performing these tasks either an ELT (Load then Transform) or ETL (Transform then Load) approach is used.
Extract
Extraction of data always comes first. This includes extracting the data to be stored in the DWH from several different data sources, e.g. ERP (Enterprise Resource Planning), CRM (Customer Relationship Management) software, relational databases and any other source that produces important data in any format. After successfully extracting the data, it’s time to either load or transform the data. Each approach has its merits, so they will be discussed separately.
Transform
First method is to transform then load (ELT). This is done by initially dividing the DWH into a staging area and a reporting area. Then, the raw data, which was extracted in the previous process, is loaded into the staging area without changing the format. Afterwards, the transformation step takes place: this includes cleaning the data, removing un-necessary data, changing data types, doing calculations, etc. This method offers more flexibility because the raw data is still available after transforming it. Also, this approach is easier to develop and maintain.
The second option is to transform the data before loading it into the DWH (ETL). This requires more pre-planning, as raw data needs to be stored temporarily in a staging area (outside the DWH), in which private data, that should not be made available in the DWH, is removed. Subsequently the data should be transformed into a format which is ready to be loaded. Afterwards, data is loaded in the DWH following the chosen schema and the raw data is discarded and not accessible anymore. This approach enables the removal of sensitive private data that should not be available in the DWH in the transform part. Also, this approach offers faster and more efficient data analysis, however with the trade-off of being more complex and needing more preparation.
Load
After storing the data in a DWH, now it’s ready to be loaded to BI software to analyze and visualize the data. For example, Power BI can connect to a DWH and in order to create visualizations on demand and create reports. A well-designed star schema provides Power BI with dimension tables for filtering and grouping, and fact tables for summarization.
Slowly Changing Dimensions (SCD)
Since a DWH stores historical data, an important aspect of its design is what is known as slowly changing dimensions SCD. SCD is any dimension that can change over time, e.g., product price or client information. There are different ways of dealing with SCDs, the most frequently used are the following:
SCD1 simply overwrites old values with new ones e.g., overwriting employee address with a new address, as the old address of an employee is not needed anymore.
The other, more frequently used option is SCD2, which adds a new row whenever the value changes. This can be done in several ways, e.g., using a validity flag which specifies if this is the current value or not, as seen in the following example of an employee title:
| employee_id | employee_name | employee_title | current_flag |
| 123 | John Doe | Junior Data Engineer | N |
| 123 | John Doe | Senior Data Engineer | Y |
Another way for SCD2 is having a start and end date of validity for each entry. The following is the same example as before, but using validity dates instead:
| employee_id | employee_name | employee_title | start_date | end_date |
| 123 | John Doe | Junior Data Engineer | 2021-01-01 | 2022-01-01 |
| 123 | John Doe | Senior Data Engineer | 2022-01-01 | null |
There are other types of Slowly Changing Dimensions that are less frequently used, e.g. saving only the current and previous values, the use of a history table or even mixture of different types. SCDs add complexity to DWH design and are expensive to store and maintain, as they require saving duplicated data as well as updating data in a more complex way. That is why the method of dealing with SCDs should be carefully selected and designed.
Data Vault
A relatively new approach called Data Vault and its successor Data Vault 2.0 can significantly simplify the process of maintaining slowly changing dimensions. Data Vault focused only on loading data into a DWH, while Data Vault 2.0 includes methodology for the whole DWH solution from development to delivery and automation. Data Vault as a methodology was built to introduce new ways of working with enterprise level data architecture, with focus on agility, scalability, flexibility, auditability and consistency. Data Vault consists of three main components as follows:
- Hubs: Represent entities of interest from a business perspective, they contain a list of unique business keys which are not likely to change.
- Links: Connect Hubs; also they may record a transaction, composition or any kind of relationship between different hubs.
- Satellites: Connect to a parent Hub or Link providing it with needed metadata, representing a point in time that can answer the question “what did we know when?”
The following is a simple example of Data Vault modeling with two hubs(blue), one link(green) and four satellites(yellow):
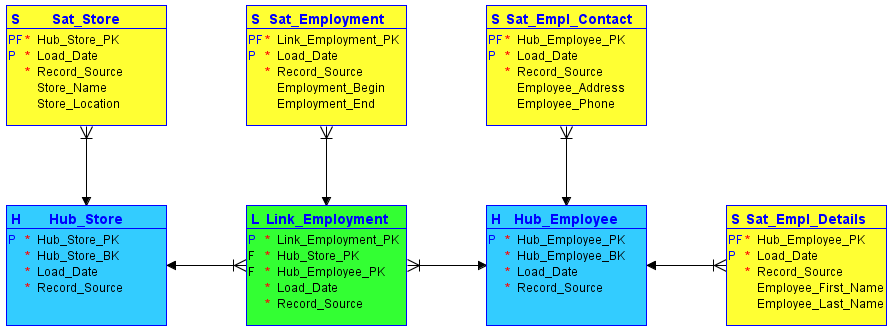
Data Vault modeling offers various advantages over classical data models including increased flexibility gained by having two diferent kinds of rules: hard rules, which are rules that should never change, e.g. data types and soft rules, which are rules that can change according to the business needs, e.g. relations between different components. Also, it offers increased scalability with larger amount of data. Another benefit is the improved method of dealing with SCDs, as these changing dimensions are stored separately in satellites which are linked to a parent Hub or Link.


