
Quelle Bild: Tobias Fischer Unsplash
Data Warehouse Einführung
Immer mehr Unternehmer und Führungskräfte möchten nach vorne gerichtet Erkenntnisse aus ihren Prozessen mittels der Datenanalyse ableiten. Damit das gelingt, müssen Daten aus den Systemen extrahiert, bereinigt und gespeichert werden. Um die Datenspeicherung und Abfrage in einer leistungsstarken Datenbank zu gewährleisten, wird i.d.R. ein Data Warehouse (DWHs) zentral im Unternehmen aufgebaut.
Der Hauptunterschied zwischen einem Data Warehouse und einer Applikationsdatenbank, wie z.B. einem CRMs besteht darin, dass letztere hauptsächlich für OLTP (Online Transaction Processing), sprich für die Online-Transaktionsverarbeitung verwendet, während ein DWH hauptsächlich für das OLAP (Online Analytical Processing) also der Online-Analyseverarbeitung eingesetzt wird. Kurz gesagt: OLTP-Systeme konzentrieren sich auf Transaktionen und den täglichen Betrieb, wohingegen OLAP-Systeme anhand historischer Daten für die Entscheidungsfindung verwendet werden. DWHs können mit einer breiten Palette von Werkzeugen entwickelt werden, z. B. PostgreSQL, Python, SQL, Knime usw.
Inhaltsverzeichnis
Daten Modelle
Was ist ein Star Schema?
Das Data Warehouses wird nach einer standardisierten Form entworfen, die als Star Schema bezeichnet wird. Das Star Schema erhielt seinen Namen, weil es aus zwei Hauptkomponenten besteht: einer Faktentabelle in der Mitte des logischen Diagramms des Schemas, die mit mehreren Dimensionstabellen verbunden ist, wie in der folgenden Abbildung dargestellt. In der Faktentabelle werden alle Ereignisse (Fakten) gespeichert. Bei diesen Ereignissen kann es sich um beliebige Beobachtungen handeln, die wir in möglichst granularer Form speichern wollen. Die andere Komponente, d.h. die Dimensionstabellen, beschreiben die Geschäftseinheiten, z.B. Kunden, Produkte oder sogar die Zeit.
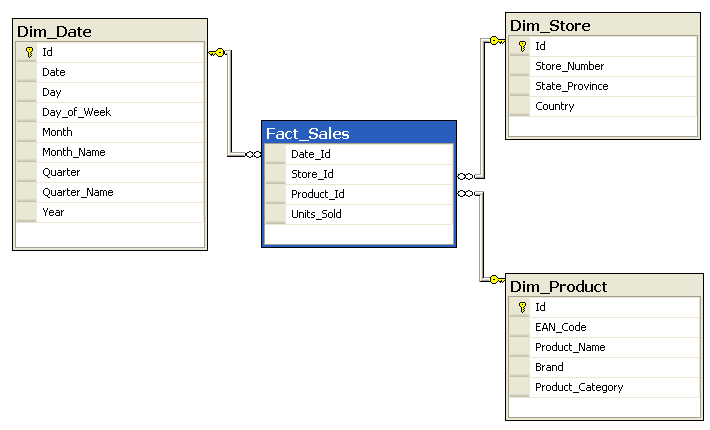
Star Schema vs. Snowflake Schema
Obwohl das Star Schema einfach und schnell ist, ist es für einige Anwendungsfälle nicht der beste Ansatz. Dementsprechend wird ein anderer bekannter Ansatz, das Snowflake Schema, benötigt. Der Unterschied zwischen diesen beiden Schemata besteht darin, dass das Snowflake Schema Daten in einer normalisierten Form speichert, während das Star Schema denormalisiert ist. Das heißt, anstatt alles, was mit einer bestimmten Dimension zusammenhängt, in einer einzigen Tabelle zu speichern (Star Schema), teilt das Snowflake Schema Dimensionstabellen in weitere Dimensionstabellen auf, die Lookup-Tabellen genannt werden. Diese können wiederum in weitere Tabellen aufgeteilt werden, wie in der nächsten Abbildung zu sehen ist. Dadurch kann das Snowflake Schema die dritte Normalform 3NF einhalten. Das Snowflake Schema ist zwar komplexer und langsamer als das einfache Star Schema, benötigt aber weniger Speicherplatz für Daten und ist weniger anfällig für Dateninkonsistenzen. Dies kann beim Umgang mit enormen Datenmengen von entscheidender Bedeutung sein.
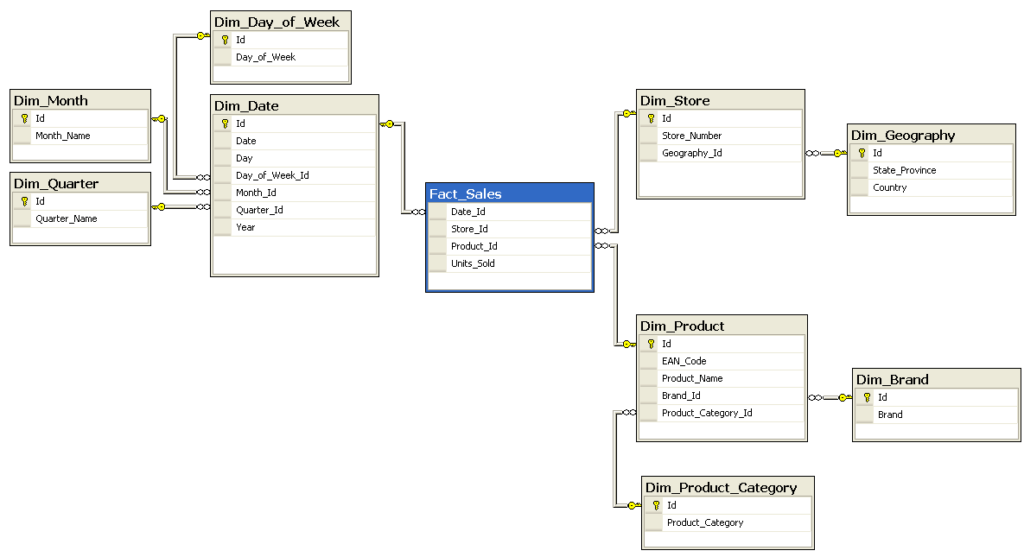
Aufbau eines Data Warehouse: ELT/ETL
Nach der Auswahl des am besten geeigneten Schemas besteht der nächste Schritt darin, die Datentabellen zu füllen und das DWH zum Laufen zu bringen. In diesem Zusammenhang sind drei Hauptaufgaben zu erledigen: Extrahieren, Laden und Transformieren. Je nach der Reihenfolge, in der diese Aufgaben ausgeführt werden, wird entweder ein ELT- (Laden und dann Transformieren) oder ein ETL-Ansatz (Transformieren und dann Laden) verwendet.
Extract
Die Extraktion von Daten steht immer an erster Stelle. Dazu gehört das Extrahieren der Daten, die im DWH gespeichert werden sollen, aus verschiedenen Datenquellen, z. B. ERP (Enterprise Resource Planning), CRM (Customer Relationship Management)-Software, relationalen Datenbanken und jeder anderen Quelle, die wichtige Daten in einem beliebigen Format liefert. Nachdem die Daten erfolgreich extrahiert wurden, müssen sie nun entweder geladen oder transformiert werden. Beide Ansätze ihre seine Vorzüge, daher werden sie hier separat behandelt.
Transform
Die erste Methode ist zuerst Transformieren und dann Laden (ELT). Dabei wird das DWH zunächst in einen Staging- und einen Reporting-Bereich unterteilt. Anschließend werden die Rohdaten, die im vorangegangenen Prozess extrahiert wurden, ohne Änderung des Formats in den Staging-Bereich geladen. Danach erfolgt der Transformationsschritt: Dazu gehört das Bereinigen der Daten, das Entfernen nicht benötigter Daten, das Ändern von Datentypen, das Durchführen von Berechnungen usw. Diese Methode bietet eine große Flexibilität, da die Rohdaten auch nach der Umwandlung noch verfügbar sind. Zudem gestaltet sich die Entwicklung und Wartung bei diesem Ansatz einfacher.
Die zweite Möglichkeit besteht darin, die Daten vor dem Laden in das DWH zu transformieren (ETL). Dies erfordert mehr Vorausplanung, da die Rohdaten vorübergehend in einem Staging-Bereich (außerhalb des DWH) zwischengespeichert werden müssen. Dort werden private Daten, die nicht im DWH verfügbar gemacht werden sollen, entfernt. Anschließend müssen die Daten in ein ladetaugliches Format transformiert werden. Wenn dies passiert ist, werden die Daten nach dem gewählten Schema in das DWH geladen und die Rohdaten werden verworfen. Dieser Ansatz ermöglicht die Entfernung sensibler privater Daten, die im DWH nicht verfügbar sein sollten, im Transformationsbereich. Außerdem bietet dieser Ansatz eine schnellere und effizientere Datenanalyse, allerdings mit dem Nachteil, dass er komplexer ist und mehr Vorbereitung erfordert.
Load
Nachdem die Daten in einem DWH gespeichert wurden, können sie nun in eine BI-Software geladen werden, um die Daten zu analysieren und zu visualisieren. Power BI kann beispielsweise eine Verbindung zu einem DWH herstellen, um bei Bedarf Visualisierungen und Berichte zu erstellen. Ein gut konzipiertes Star Schema bietet Power BI Dimensionstabellen zum Filtern und Gruppieren sowie Faktentabellen für die Zusammenfassung.
Slowly Changing Dimensions (SCDs)
Da ein DWH historische Daten speichert, ist ein wichtiger Aspekt seines Designs sind sogenannte Slowly Changing Dimensions SCD (dt.: sich langsam ändernde Dimensionen). Eine SCD ist jede Dimension, die sich im Laufe der Zeit ändern kann, z. B. ein Produktpreis oder Kundeninformationen. Es gibt verschiedene Möglichkeiten, SCDs zu behandeln, die am häufigsten verwendeten sind die folgenden:
SCD1 überschreibt einfach alte Werte mit neuen. So wird z. B. die Adresse eines Mitarbeiters mit einer neuen Adresse überschrieben, da die alte Adresse eines Mitarbeiters nicht mehr benötigt wird.
Die andere, häufiger verwendete Option ist SCD2, die eine neue Zeile hinzufügt, sobald sich der Wert ändert. Dies kann auf verschiedene Weise geschehen, z. B. durch Verwendung eines Gültigkeitsflags, das angibt, ob es sich um den aktuellen Wert handelt oder nicht, wie im folgenden Beispiel für einen Angestelltentitel:
| employee_id | employee_name | employee_title | current_flag |
| 123 | John Doe | Junior Data Engineer | N |
| 123 | John Doe | Senior Data Engineer | Y |
Eine andere Möglichkeit für SCD2 ist die Angabe eines Anfangs- und Enddatums für die Gültigkeit jedes Eintrags. Es folgt dasselbe Beispiel wie zuvor, aber mit Gültigkeitsdaten:
| employee_id | employee_name | employee_title | start_date | end_date |
| 123 | John Doe | Junior Data Engineer | 2021-01-01 | 2022-01-01 |
| 123 | John Doe | Senior Data Engineer | 2022-01-01 | null |
Es gibt noch weitere Arten von Slowly Changing Dimensions, die weniger häufig verwendet werden, z. B. die Speicherung nur der aktuellen und vorherigen Werte, die Verwendung einer Historientabelle oder sogar eine Mischung verschiedener Typen. SCDs erhöhen die Komplexität des DWH-Designs und sind teuer in der Speicherung und Pflege, da sie die Speicherung doppelter Daten sowie die Aktualisierung von Daten auf komplexere Weise erfordern. Aus diesem Grund sollte die Methode für den Umgang mit SCDs sorgfältig ausgewählt und konzipiert werden.
Data Vault
Ein relativ neuer Ansatz namens Data Vault und sein Nachfolger Data Vault 2.0 können den Prozess der Pflege von SCDs erheblich vereinfachen. Data Vault konzentrierte sich nur auf das Laden von Daten in ein DWH, während Data Vault 2.0 eine Methodik für die gesamte DWH-Lösung von der Entwicklung bis zur Bereitstellung und Automatisierung umfasst. Data Vault als Methodik wurde entwickelt, um neue Wege für die Arbeit mit Datenarchitekturen auf Unternehmensebene einzuführen, wobei der Schwerpunkt auf Agilität, Skalierbarkeit, Flexibilität, Prüfbarkeit und Konsistenz liegt. Data Vault besteht aus den folgenden drei Hauptkomponenten:
- Hubs (Knotenpunkte): Sie enthalten eine Liste von eindeutigen Geschäftsschlüsseln, die sich wahrscheinlich nicht ändern werden.
- Links (Verknüpfungen): Verbinden Hubs; sie können eine Transaktion, eine Zusammensetzung oder jede andere Art von Beziehung zwischen verschiedenen Hubs darstellen.
- Satellites: Stellen eine Verbindung zu einem übergeordneten Hub oder Link her und versorgen ihn mit den benötigten Metadaten, die einen Zeitpunkt darstellen, der die Frage „Was wussten wir wann?“ beantworten kann.
Es folgt ein einfaches Beispiel für die Modellierung von Data Vault mit zwei Hubs (blau), einem Link (grün) und vier Satelliten (gelb):
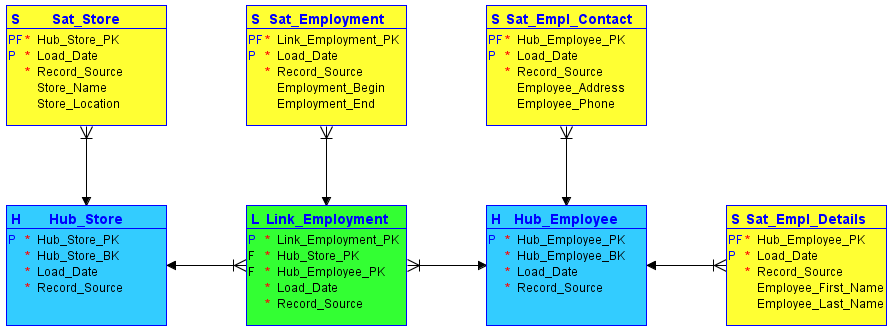
Die Modellierung von Data Vaults bietet verschiedene Vorteile gegenüber klassischen Datenmodellen, darunter eine höhere Flexibilität, die durch zwei verschiedene Arten von Regeln erreicht wird: harte Regeln, die sich nie ändern sollten, z. B. Datentypen, und weiche Regeln, die sich je nach Geschäftsanforderungen ändern können, z. B. Beziehungen zwischen verschiedenen Komponenten. Außerdem bietet es eine bessere Skalierbarkeit bei größeren Datenmengen. Ein weiterer Vorteil ist die verbesserte Methode zum Umgang mit SCDs, da diese sich ändernden Dimensionen separat in Satelliten gespeichert werden, die mit einem übergeordneten Hub oder Link verbunden sind.


