Was ist Microsoft Fabric und wie löst OneLake Datensilos mit Echtzeit Power BI auf?
Microsoft Fabric OneLake löst Datensilos mit Delta-Parquet & Direct Lake Technologien auf. Nahtlose Integration in Power BI Dashboards.

Microsoft Fabric OneLake löst Datensilos mit Delta-Parquet & Direct Lake Technologien auf. Nahtlose Integration in Power BI Dashboards.
Microsoft Fabric OneLake ist ein zentraler, cloudbasierter Datenspeicher, der Datensilos auflöst, indem er alle Unternehmensdaten im offenen Delta-Parquet-Format bündelt. Er ermöglicht Tools wie Power BI den Zugriff in Echtzeit (Direct Lake), ohne Daten kopieren zu müssen – und ersetzt damit fragmentierte Import-Pipelines durch eine Single Source of Truth.
Microsoft Fabric ist eine KI-gestützte All-in-One-Analytics-Plattform, die Datenintegration, Data Engineering, Data Warehousing und Power BI in einer einzigen SaaS-Umgebung vereint. Statt isolierter Einzelprodukte entsteht eine gemeinsame Arbeitsumgebung, in der alle datengetriebenen Prozesse zusammenlaufen.
Im Zentrum steht der OneLake – oft als „OneDrive for Data" bezeichnet. Dieser unternehmensweite Datenspeicher bündelt sämtliche Daten im offenen Delta-Parquet-Format und schafft damit eine echte Single Source of Truth.
Ein klassischer Data Lake (z. B. Azure Data Lake Storage) ist ein reiner Speicher ohne eingebaute Governance, Sicherheit oder Struktur – Teams legen Daten ab, aber ohne zentrale Regeln entsteht schnell ein "Data Swamp" mit unklarer Datenherkunft, fehlender Dokumentation und doppelten Kopien.
OneLake ist kein weiterer Data Lake, sondern eine governierte Datenschicht über dem gesamten Fabric-Tenant . Er wird automatisch mit jedem Tenant bereitgestellt – es gibt genau einen pro Organisation. Zugriffsrechte, Domänen-Zuordnung, Endorsement und Lineage sind nativ eingebaut, nicht nachträglich aufgesetzt.
Während bei klassischen Data Lakes jedes Projekt seinen eigenen Speicher provisioniert (Storage-Account-Wildwuchs), erzwingt OneLake eine hierarchische Struktur (Tenant → Workspace → Lakehouse/Warehouse), die Wildwuchs architektonisch verhindert.
OneLake speichert alles im Delta-Parquet-Format – ein klassischer Data Lake erlaubt beliebige Formate (CSV, JSON, Parquet, proprietär), was Interoperabilität erschwert und Vendor Lock-in begünstigt.
Das Fabric Warehouse bietet einen vollständig verwalteten SQL-Endpunkt mit T-SQL-Unterstützung, der sich bewusst an bestehende SQL-Server-Kenntnisse richtet – der Einstieg für klassische BI-Teams ist damit niedrigschwellig.
Zusätzlich existiert der SQL Analytics Endpoint im Lakehouse, der automatisch eine SQL-Sicht auf die Delta-Tabellen erzeugt – ohne Daten zu kopieren. Das bedeutet: Auch Lakehouse-Daten sind sofort per SQL abfragbar, ohne ein separates Warehouse aufzubauen.
Der entscheidende Unterschied zur klassischen Welt: In Fabric teilen sich Warehouse und Lakehouse denselben OneLake-Speicher . Es gibt keine Datenverschiebung zwischen den beiden – es sind zwei Zugriffsparadigmen (SQL vs. Spark) auf dieselbe physische Datenbasis.
Direct Lake Mode in Power BI liest Daten direkt aus dem OneLake im Delta-Format, ohne sie vorher in ein In-Memory-Modell zu importieren. Das eliminiert den klassischen Import-/DirectQuery-Kompromiss und ermöglicht schnelle Abfragen auf sehr großen Datenmengen.
Klassisches BI-Reporting arbeitet in Batch-Zyklen (nächtliche Ladeläufe, stündliche Refreshes) – die Daten sind immer mindestens so alt wie der letzte Ladelauf.
Fabric bietet drei Stufen der Aktualität: Batch (Data Pipeline/Dataflow Gen2), Near-Realtime (Mirroring mit Delta-Synchronisation im Minutentakt) und Echtzeit (Eventstream/Real-Time Intelligence mit Sekundenlatenz).
Eventstream nimmt Daten aus Quellen wie Azure Event Hubs, IoT Hub oder Kafka entgegen und leitet sie an KQL-Datenbanken (Kusto Query Language) weiter, die für zeitreihenbasierte Analysen optimiert sind.
Real-Time Dashboards in Fabric nutzen KQL-Datenbanken und aktualisieren sich automatisch – ohne manuellen Refresh. Das ist ein fundamentaler Unterschied zu klassischen Power-BI-Dashboards, die auf geplante Aktualisierungsintervalle angewiesen sind.
Reflexe (Reflex) ermöglichen es, automatische Aktionen auszulösen, wenn bestimmte Datenmuster erkannt werden – z. B. eine Warnung bei Umsatzeinbruch oder eine automatische Nachbestellung bei Lagerbestandsunterschreitung.
Endorsement (Promoted / Certified) kennzeichnet vertrauenswürdige Datenartefakte organisationsweit sichtbar – Nutzer erkennen sofort, ob ein Dataset geprüft und freigegeben ist oder ob es sich um eine explorative Arbeitskopie handelt.
Data Lineage zeigt den vollständigen Datenfluss vom Quellsystem über Transformationen bis zum fertigen Report – bei Datenfehlern lässt sich die Ursache entlang der Kette zurückverfolgen, statt in isolierten Systemen zu suchen.
Datahub & Metadaten-Management ermöglicht die zentrale Beschreibung, Kategorisierung und Suche von Datenobjekten. Ohne gepflegte Metadaten ist selbst der beste zentrale Speicher wertlos – OneLake Data Hub adressiert genau dieses Problem.
Delta Lake als Qualitätsschicht: ACID-Transaktionen stellen sicher, dass Datenladungen entweder vollständig oder gar nicht durchgeführt werden – halbfertige, inkonsistente Datenstände, wie sie bei klassischen CSV-Importen entstehen, sind ausgeschlossen. Schema Enforcement verhindert, dass fehlerhafte Datenstrukturen unbemerkt eingeladen werden.
Purview-Integration (Microsoft Purview) erweitert die Governance um Datenschutz-Labels (Sensitivity Labels), automatische Klassifizierung sensibler Daten und Compliance-Monitoring – Datenqualität wird damit um die Dimension Datenschutz und regulatorische Konformität ergänzt.
Monitoring Hub bietet eine zentrale Übersicht über alle laufenden und abgeschlossenen Aktivitäten (Refreshes, Pipeline-Runs, Spark-Jobs) – Fehler und Performance-Probleme werden frühzeitig sichtbar, bevor sie die Datenqualität beeinträchtigen.
Wer heute mit Reporting-Tools wie Power BI, Tableau, Qlik oder Excel arbeitet, kennt die Situation: Jede Abteilung pflegt eigene Datenquellen, importiert Daten separat und erstellt isolierte Berichte. Das Ergebnis sind klassische Datensilos, die zu inkonsistenten Kennzahlen, doppelter Datenhaltung und unnötigem Pflegeaufwand führen.
Genau dieses Problem adressiert Microsoft Fabric mit einem grundlegend anderen Architekturansatz.
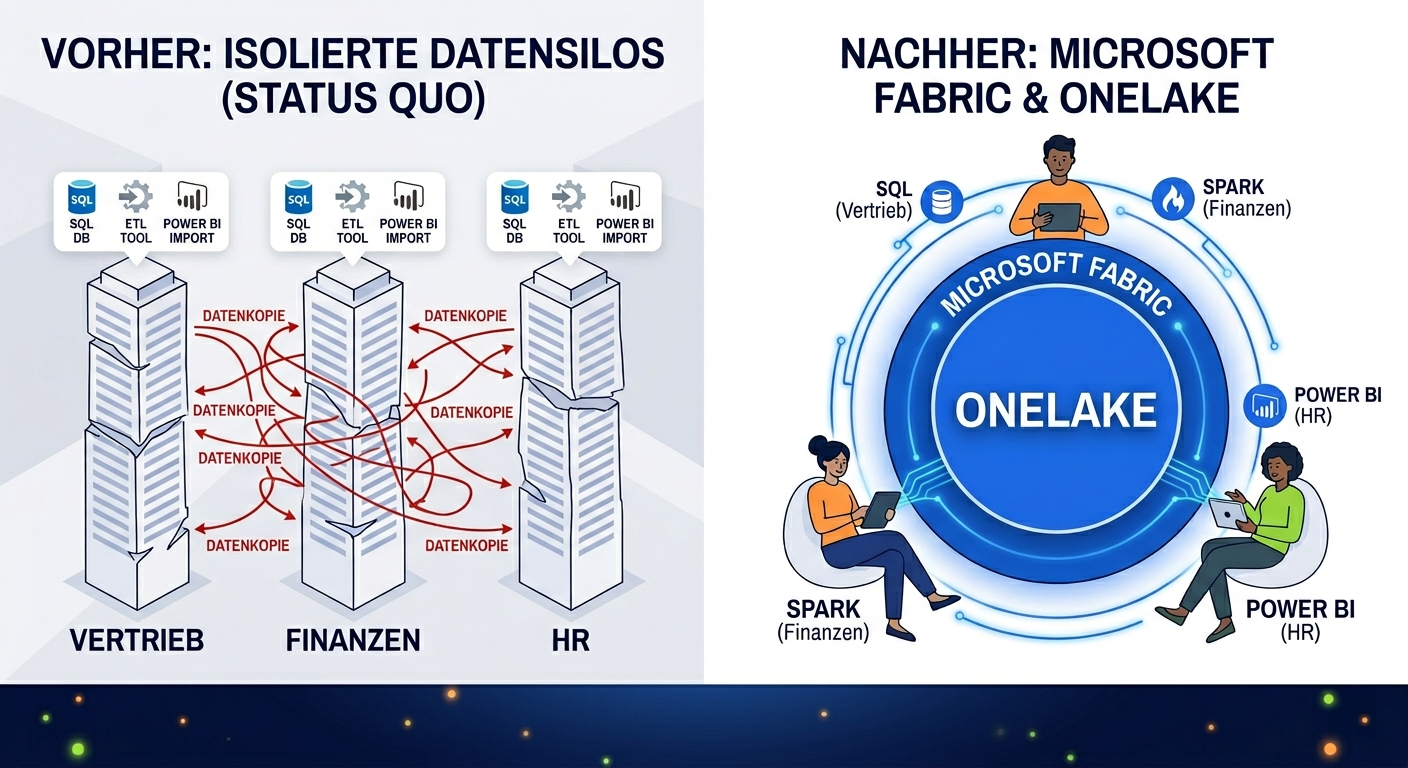
OneLake speichert alle Daten zentral an einem Ort. Dadurch ergeben sich drei wesentliche Veränderungen:
Redundante Kopien entfallen. Alle Abteilungen greifen auf dieselbe Datenbasis zu, statt jeweils eigene Kopien zu pflegen. Das reduziert Inkonsistenzen und Speicherkosten.
Verschiedene Tools nutzen dieselbe Quelle. Ob SQL-Abfragen, Spark-Analysen oder Power-BI-Berichte – durch das offene Delta-Parquet-Format ist keine Konvertierung zwischen Engines nötig.
Abteilungen benötigen keine eigenen Speicherlösungen mehr. Der zentrale OneLake ersetzt dezentrale Insellösungen und vereinfacht die IT-Landschaft.
Der entscheidende Unterschied liegt in der Architektur. Klassische Data Warehouses speichern ausschließlich strukturierte, vorab transformierte Daten in starren Schemata. Rohdaten und unstrukturierte Formate bleiben außen vor.
Fabric verfolgt einen Lakehouse-Ansatz , der beide Welten vereint: strukturierte Abfragen auf Warehouse-Niveau und gleichzeitig die Flexibilität, Rohdaten, JSON, Bilder oder Logs im selben OneLake zu halten und erst bei Bedarf zu transformieren.
| Kriterium | Klassisches Data Warehouse | Microsoft Fabric OneLake |
|---|---|---|
| Datenformate | Nur strukturierte Daten | Strukturiert, semi-strukturiert, unstrukturiert |
| Datenhaltung | Redundante Kopien pro Abteilung | Zentrale Single Source of Truth |
| Zugriff | Eigene Import-Pipelines je Tool | Direkter Zugriff über Shortcuts und Direct Lake |
| Format | Proprietär je Anbieter | Offenes Delta-Parquet-Format |
| Skalierung | Manuelle Infrastrukturverwaltung | Serverless, automatische Skalierung |
Shortcuts verbinden externe Quellen wie Azure SQL, Amazon S3 oder Google Cloud Storage direkt mit dem OneLake – ohne Daten physisch kopieren zu müssen. So lassen sich bestehende Systeme einbinden, ohne sie zu migrieren.
Mirroring spiegelt operative Datenbanken in Echtzeit in den OneLake, ohne klassische ETL-Prozesse. Reporting-Daten sind dadurch immer aktuell.
Direct Lake Modus ermöglicht Power BI den direkten Zugriff auf das Warehouse in Echtzeit. Zeitintensive Datenimporte und geplante Aktualisierungen entfallen.
T-SQL-Kompatibilität sorgt dafür, dass Analysten ihre gewohnten SQL-Kenntnisse weiter nutzen können, um Abfragen direkt im OneLake auszuführen.
Dataflows Gen2 bieten eine modernisierte Oberfläche für Datenaufbereitung und -transformation, die den bisherigen Workflow aus Data Factory und Power Query zusammenführt.
Keine Datensilos: Der zentrale OneLake schafft eine konsistente Datenbasis für alle Abteilungen.
Echtzeit-Reporting: Der Direct Lake Modus eliminiert Import-Verzögerungen in Power BI.
Kosteneinsparung: Lokale Speicherlösungen und redundante Infrastruktur können entfallen.
Kein Vendor Lock-in auf Datenebene: Das offene Delta-Parquet-Format ermöglicht den Zugriff auch mit Nicht-Microsoft-Tools.
Serverless Skalierung: Ressourcen passen sich automatisch an die Abfrageintensität an.
Migrationsaufwand: Die initiale Umstellung bestehender Systeme erfordert erhebliche Planung und Ressourcen.
Plattformabhängigkeit: Trotz offener Datenformate entsteht auf Plattformebene eine starke Bindung an das Microsoft-Ökosystem.
Kostenkontrolle: Dynamische Kapazitätskosten (F-SKUs) können bei großen Datenmengen schnell steigen und erfordern aktives Monitoring.
Single Point of Failure: Die Zentralisierung erhöht die Abhängigkeit von stabilen Cloud-Verbindungen.
Der „Hidden Cost"-Faktor: Viele Unternehmen unterschätzen die sogenannte „Data Gravity". Nur weil OneLake Shortcuts bietet, heißt das nicht, dass bestehende Datenleitungen aus On-Premise-Systemen unendlich belastbar sind. Eine hybride Übergangsstrategie ist hier oft der realistischere Weg.
Fabric ist kein reines Enterprise-Produkt. Gerade mittelständische Unternehmen, die zwischen 500 GB und 10 TB an Daten bewegen, profitieren besonders – vor allem, wenn sie heute an langsamen SQL-Servern, teuren Snowflake-Instanzen oder unübersichtlichen Excel-Landschaften verzweifeln.
Typische Signale, dass sich ein Umstieg lohnt:
Mehrere Abteilungen pflegen eigene Power-BI-Datenmodelle mit überlappenden Datenquellen.
Geplante Aktualisierungen (Scheduled Refreshes) dauern Stunden und blockieren Kapazitäten.
Die IT verwaltet parallele Systeme für Staging, Transformation und Reporting.
Fachabteilungen fordern Self-Service-Zugriff auf aktuelle Daten, ohne auf die IT warten zu müssen.
Wer sich in zwei oder mehr dieser Punkte wiederfindet, sollte OneLake ernsthaft evaluieren.
| Begriff | Beschreibung | Vorteile ggü. klassischer BI | Nachteile | Nutzen für das Unternehmen |
|---|---|---|---|---|
| Zentraler Datenspeicher (OneLake) | Einheitlicher, unternehmensweiter Speicherort für alle Daten innerhalb von Microsoft Fabric, der als "Single Source of Truth" dient. | Schafft eine "Single Source of Truth" und vermeidet redundante, inkonsistente Datenstände. Vereinfacht die Datenverwaltung und -governance durch Zentralisierung. Ermöglicht unternehmensweite Analysen und Reporting auf Basis eines einheitlichen Datenbestands. | Erfordert umfangreiche Anpassungen bestehender Datenarchitekturen und -prozesse. Zentralisierung kann bei unzureichendem Rechte- und Zugriffsmanagement zu Sicherheitsrisiken führen. Hohe Anforderungen an Speicherkapazität und Skalierbarkeit. Möglicher Single Point of Failure bei technischen Störungen. Erhöhter Koordinations- und Abstimmungsbedarf zwischen verschiedenen Datenverantwortlichen und -nutzern. | Eliminiert Datensilos und stellt sicher, dass alle Abteilungen auf derselben Datenbasis arbeiten. Beschleunigt unternehmensweite Analysen und reduziert Abstimmungsaufwand zwischen Teams. |
| Shortcuts (Verknüpfungen) | Logische Verweise auf Daten in externen Quellen oder anderen Cloud-Speichern, die eine Integration ohne physische Datenverschiebung ermöglichen. | Ermöglicht die effiziente Integration von Daten aus verschiedenen Quellen ohne physische Datenverschiebung. Reduziert Komplexität und Zeitaufwand bei der Datenintegration. Vereinfacht die Einbindung von Daten aus externen Systemen und Clouds. | Erfordert stabile und performante Netzwerkverbindungen zu den Datenquellen. Abhängigkeit von der Verfügbarkeit und Zuverlässigkeit der verknüpften Systeme. Mögliche Latenzzeiten beim Zugriff auf verknüpfte Daten. Erhöhte Komplexität bei der Verwaltung und Überwachung zahlreicher Verknüpfungen. Potenzielle Sicherheitsrisiken durch Zugriff auf externe Datenquellen. | Spart Speicherkosten und vermeidet Datenredundanz. Ermöglicht schnelle Integration neuer Datenquellen ohne aufwändige Migrationsprojekte. |
| Mirroring (Spiegelung) | Kontinuierliche, automatische Replikation operativer Datenbanken in den OneLake für Echtzeit-Reporting. | Ermöglicht Echtzeit-Reporting durch sofortige Spiegelung operativer Datenbanken. Eliminiert zeitaufwändige ETL-Prozesse und Datenaktualisierungen. Gewährleistet konsistente und aktuelle Daten für Analysen und Berichte. | Erhöhter Ressourcenbedarf durch kontinuierliche Spiegelung großer Datenmengen. Potenzielle Auswirkungen auf die Performanz der Quelldatenbanken während der Spiegelung. Erfordert sorgfältige Planung und Überwachung, um Konflikte und Inkonsistenzen zu vermeiden. Mögliche Datenredundanz und erhöhter Speicherbedarf. Herausforderungen bei der Gewährleistung der Datenintegrität zwischen Quelle und Ziel. | Entscheidungsträger arbeiten stets mit aktuellen Daten statt mit veralteten Tages- oder Wochenberichten. Reduziert den operativen Aufwand für Datenaktualisierungen erheblich. |
| Vereinheitlichung von Tools | Integration aller Datenverarbeitungsschritte – von Ingestion über Engineering bis Reporting – in einer durchgängigen Plattform mit einheitlicher Oberfläche. | Bietet eine integrierte, durchgängige Plattform für Datenintegration, Engineering und Reporting. Reduziert Schulungsaufwand und Einarbeitungszeit durch einheitliche Benutzeroberflächen. Verbessert die Zusammenarbeit und Kommunikation zwischen verschiedenen Datenteams. | Abhängigkeit von der Weiterentwicklung und dem Support der Fabric-Plattform durch Microsoft. Mögliche Einschränkungen bei der Integration von Drittanbieter-Tools und -Systemen. Erfordert Anpassungen bestehender Arbeitsabläufe und Prozesse. Potenzielle Lernkurve und Widerstand bei der Umstellung. Geringere Flexibilität bei der Auswahl von Analysewerkzeugen. | Senkt die Total Cost of Ownership durch Konsolidierung der Toollandschaft. Fördert bereichsübergreifende Zusammenarbeit und beschleunigt Projektdurchlaufzeiten. |
| Open Data Format | Verwendung offener, herstellerunabhängiger Datenformate (z. B. Delta/Parquet) zur Vermeidung von Vendor Lock-in. | Vermeidet Herstellerabhängigkeit und "Vendor Lock-in" durch Verwendung eines offenen Datenformats. Ermöglicht Interoperabilität und Flexibilität bei der Nutzung verschiedener Tools. Fördert Datendemokratisierung und -austausch innerhalb und außerhalb des Unternehmens. | Erfordert Anpassungen bestehender Datenformate und -strukturen. Kompatibilität und Performance im Vergleich zu proprietären Formaten möglicherweise eingeschränkt. Potenzielle Herausforderungen bei Datensicherheit und -schutz im offenen Format. Möglicher Mehraufwand bei Konvertierung und Anpassung. Geringere Kontrolle über Datennutzung und -verbreitung. | Sichert langfristige strategische Flexibilität bei der Plattformwahl. Erleichtert die Zusammenarbeit mit externen Partnern und den Datenaustausch über Systemgrenzen hinweg. |
| Lakehouse | Hybridarchitektur aus Data Lake und Data Warehouse in einem System für strukturierte und unstrukturierte Daten. | Keine getrennten Systeme mehr für strukturierte und unstrukturierte Daten. Entfällt die aufwändige Datenverschiebung zwischen Lake und Warehouse. Unterstützt sowohl SQL-Analysten als auch Data Scientists auf derselben Datenbasis. | Neues Architekturkonzept erfordert Umdenken bei erfahrenen BI-Teams. SQL-Performance kann bei komplexen Abfragen hinter spezialisierten Warehouses zurückbleiben. Datenmodellierung ist weniger strikt, was ohne klare Governance zu "Datenchaos" führen kann. | Beschleunigt die Time-to-Insight erheblich. Ermöglicht neben klassischen Reports auch KI- und ML-Anwendungsfälle auf denselben Daten, was Innovationspotenziale erschließt. |
| Warehouse | Vollständig verwaltetes relationales Data Warehouse innerhalb von Fabric, optimiert für SQL-basierte Analysen. | Kein eigener Server-Betrieb oder Infrastrukturmanagement nötig. Automatische Skalierung der Rechenleistung. Nahtlose Integration mit allen anderen Fabric-Komponenten statt isolierter Datenbank-Silos. | Geringere Kontrolle über Infrastruktur und Feintuning im Vergleich zu selbst betriebenen SQL-Server-Instanzen. Abhängigkeit von Microsofts Kapazitätsmodell und Preisgestaltung. Manche fortgeschrittene T-SQL-Features sind noch nicht vollständig unterstützt. | Senkt Betriebskosten und Personalaufwand für Datenbankadministration. Bestehende SQL-Kenntnisse bleiben nutzbar, während die Vorteile der integrierten Plattform genutzt werden. |
| Workspace | Logischer Container zur Organisation von Artefakten und Steuerung von Zugriffsrechten. | Ersetzt fragmentierte Ordnerstrukturen und isolierte Projektablagen. Rollenbasierte Zugriffskontrolle direkt integriert statt über separate Systeme. Fördert teamübergreifende Zusammenarbeit auf gemeinsamen Ressourcen. | Bei unkontrolliertem Wachstum droht "Workspace-Sprawl" mit Unübersichtlichkeit. Berechtigungsmodell kann bei komplexen Organisationsstrukturen schwer abzubilden sein. Namenskonventionen und Governance müssen aktiv durchgesetzt werden. | Schafft klare Verantwortlichkeiten und Transparenz über Zugriffsrechte. Reduziert das Risiko von Schatten-IT und unkontrollierten Dateninseln. |
| Capacity (Kapazitätseinheiten) | Zugewiesene Rechenleistung (CU – Capacity Units), die alle Fabric-Workloads antreibt. | Kein Kauf und Betrieb eigener Hardware mehr. Flexible Skalierung nach Bedarf statt starrer Serverkapazitäten. Übergreifendes Kostenmodell statt separater Lizenzen für ETL-Tool, Datenbank und Reporting-Server. | Kostenmodell anfangs schwer kalkulierbar, da alle Workloads aus einem gemeinsamen Pool schöpfen. Bei Fehlplanung kann eine Workload die Performance anderer beeinträchtigen ("Noisy Neighbor"). Laufende Kosten können bei intensiver Nutzung klassische On-Premise-Lösungen übersteigen. | Wandelt hohe Investitionskosten (CAPEX) in planbare Betriebskosten (OPEX) um. Ermöglicht schnelles Hochskalieren bei Lastspitzen ohne Vorlaufzeit für Hardware-Beschaffung. |
| Dataflow Gen2 | Low-Code-/No-Code-Tool zur Datentransformation und -aufbereitung mittels Power Query. | Deutlich einfacher als klassische ETL-Tools wie SSIS. Auch Fachanwender ohne Programmierkenntnisse können Datentransformationen erstellen. Visuelle Oberfläche beschleunigt die Entwicklung erheblich. | Für hochkomplexe Transformationslogik weniger geeignet als codebasierte Lösungen. Performance bei sehr großen Datenmengen kann limitiert sein. Debugging und Fehlersuche in der visuellen Umgebung eingeschränkter. | Entlastet die IT-Abteilung, da Fachbereiche einfache Datenaufbereitungen selbst vornehmen können. Verkürzt die Zeit von der Datenanforderung bis zur fertigen Aufbereitung von Wochen auf Stunden. |
| Data Pipeline | Orchestrierungswerkzeug für komplexe Datenflüsse und ETL-/ELT-Prozesse, vergleichbar mit Azure Data Factory. | Integriert in die Fabric-Plattform statt separatem ETL-Server. Visuelle Orchestrierung mit Abhängigkeiten, Zeitplänen und Fehlerbehandlung. Nahtlose Anbindung an alle Fabric-Datenquellen und -Senken. | Komplexe Migrationen bestehender SSIS-Pakete oder Informatica-Jobs sind aufwändig. Manche fortgeschrittene Orchestrierungsmuster erfordern Workarounds. Monitoring und Alerting sind noch nicht so ausgereift wie bei etablierten Enterprise-ETL-Tools. | Automatisiert wiederkehrende Datenladeprozesse zuverlässig und reduziert manuelle Eingriffe. Stellt sicher, dass Entscheidungsträger morgens aktuelle Daten vorfinden. |
| Notebook | Interaktive Spark-basierte Entwicklungsumgebung für Datentransformation, Exploration und Machine Learning. | Ermöglicht explorative Datenanalyse, die mit klassischen BI-Tools nicht möglich war. Direkte Verbindung zu ML-Frameworks und -Bibliotheken. Kombination von Code, Visualisierung und Dokumentation in einem Dokument. | Erfordert Programmierkenntnisse in Python, Scala oder R. Weniger geeignet für standardisierte, wiederkehrende Reporting-Aufgaben. Spark-Ressourcenverbrauch kann bei unerfahrenen Nutzern schnell eskalieren. | Ermöglicht Data-Science- und Advanced-Analytics-Anwendungsfälle direkt auf den Unternehmensdaten. Fördert Innovation durch schnelles Prototyping. |
| Semantic Model (ehem. Dataset) | Datenmodell mit Beziehungen, Measures und KPIs als Grundlage für Power-BI-Reports. | Zentrale Definition von Geschäftskennzahlen statt redundanter Berechnungen in einzelnen Reports. Wiederverwendbarkeit über verschiedene Berichte und Dashboards. Eingebaute Sicherheit auf Zeilenebene (Row-Level Security). | Erfordert sorgfältige Modellierung und DAX-Kenntnisse. Änderungen am Modell können Auswirkungen auf zahlreiche abhängige Berichte haben. Bei sehr großen Modellen können Performance-Probleme auftreten. | Stellt sicher, dass alle Abteilungen dieselben KPIs verwenden – "Umsatz" bedeutet überall dasselbe. Eliminiert Diskussionen über abweichende Zahlen in verschiedenen Reports. |
| Eventstream / Real-Time Intelligence | Komponenten für die Verarbeitung und Analyse von Echtzeit-Datenströmen innerhalb von Fabric. | Klassische BI arbeitet mit Batch-Verarbeitung (täglich/stündlich) – hier werden Daten in Sekunden analysiert. Keine separaten Streaming-Plattformen wie Kafka nötig. Integrierte Echtzeit-Dashboards. | Nicht jeder Anwendungsfall erfordert Echtzeit – Overengineering möglich. Streaming-Architektur ist konzeptionell komplexer als Batch. Kosten steigen mit Volumen und Geschwindigkeit der Datenströme. | Ermöglicht sofortige Reaktionen auf Geschäftsereignisse – etwa Betrugserkennung, IoT-Monitoring oder Live-Kampagnensteuerung. Verschafft Wettbewerbsvorteil durch schnellere Entscheidungsfähigkeit. |
| Domain | Übergeordnete fachliche Gruppierung von Workspaces nach Geschäftsbereichen (Data-Mesh-Prinzip). | In klassischen BI-Umgebungen gibt es keine fachliche Strukturierung oberhalb einzelner Projekte. Ermöglicht dezentrale Datenverantwortung nach Data-Mesh-Prinzipien. Klare Zuordnung von Datenprodukten zu Fachbereichen. | Erfordert organisatorische Veränderungen und klare Verantwortungsverteilung. Domain-Grenzen können bei bereichsübergreifenden Daten schwer zu definieren sein. Governance-Aufwand steigt mit der Anzahl der Domains. | Stärkt die Eigenverantwortung der Fachbereiche für ihre Daten. Verhindert, dass die zentrale IT zum Engpass wird, und beschleunigt die Bereitstellung neuer Datenprodukte. |
| OneLake Data Hub | Zentraler Katalog zum Entdecken, Durchsuchen und Verwalten aller im OneLake verfügbaren Datenobjekte. | Klassische BI-Umgebungen haben oft keinen übergreifenden Katalog – Nutzer wissen nicht, welche Daten existieren. Durchsuchbar über alle Workspaces hinweg. Zeigt Herkunft, Qualität und Zertifizierung von Daten. | Nutzen hängt stark von der Qualität der Metadaten und Beschreibungen ab. Erfordert Disziplin bei der Pflege. Bei sehr großen Umgebungen kann die Auffindbarkeit trotzdem herausfordernd sein. | Reduziert die Zeit, die Mitarbeitende mit der Suche nach den richtigen Daten verbringen, drastisch. Fördert Wiederverwendung vorhandener Daten statt redundanter Neubeschaffung. |
| Delta Lake / Delta Parquet | Offenes Speicherformat mit ACID-Transaktionen, Versionierung (Time Travel) und Schema-Evolution. | Klassische BI nutzt oft proprietäre Formate, die an bestimmte Tools gebunden sind. Ermöglicht Time Travel (Rückkehr zu früheren Datenständen). Schema-Evolution ohne Downtime möglich. | Zusätzliche Komplexität durch Versionierung und Metadatenverwaltung. Regelmäßige Wartung (Vacuum, Optimize) notwendig. Nicht alle externen Tools unterstützen Delta Lake nativ. | Ermöglicht Nachvollziehbarkeit von Datenänderungen für Audit und Compliance. Fehlerhafte Datenladungen können einfach auf den letzten korrekten Stand zurückgesetzt werden. |
| Endorsement (Zertifizierung) | Qualitätskennzeichnung von Datenartefakten als "promoted" oder "certified". | In klassischen Umgebungen fehlt oft eine formale Qualitätskennzeichnung. Schafft Transparenz und Vertrauen. Lenkt Nutzer zu geprüften Datenquellen. | Zertifizierungsprozesse müssen definiert und gelebt werden. Kann zu Bürokratie führen. Nicht-zertifizierte Daten werden möglicherweise zu Unrecht ignoriert. | Erhöht das Vertrauen in Berichte und Analysen auf Vorstandsebene. Reduziert das Risiko, dass Geschäftsentscheidungen auf fehlerhaften oder veralteten Daten basieren. |
| Tenant | Oberste organisatorische Ebene, die den gesamten Fabric-Speicher und alle Workspaces eines Unternehmens umfasst. | Klassische BI hat keine vergleichbare übergreifende Organisationseinheit. Zentrale Steuerung von Sicherheitsrichtlinien, Compliance und Nutzungspolicies. Einheitliche Identitätsverwaltung über Azure Active Directory. | Multi-Tenant-Szenarien (z. B. bei Konzernstrukturen) können komplex werden. Fehlkonfigurationen auf Tenant-Ebene wirken sich auf die gesamte Organisation aus. Begrenzte Isolation zwischen Geschäftsbereichen innerhalb eines Tenants. | Bietet eine zentrale Steuerungsebene für die gesamte Daten- und Analyseplattform. Erleichtert die Einhaltung regulatorischer Anforderungen (DSGVO, Branchenvorschriften) durch einheitliche Richtlinien. |
Da OneLake den Datenzugriff für alle Abteilungen öffnet, ist eine präzise Rechteverwaltung zwingend erforderlich. Ohne klare Security- und Compliance-Regeln wird der größte Vorteil – die zentrale Verfügbarkeit – zum Risiko.
Unternehmen sollten vor der Migration ein Governance-Konzept erarbeiten, das Zugriffsrechte, Datenklassifizierung und Verantwortlichkeiten klar definiert.
Als Experten für Datenstrategie im Raum München und Kirchheim sehen wir oft, dass Unternehmen vor der Komplexität der Migration zurückschrecken. Die Erfahrung zeigt: Wer Governance von Anfang an mitdenkt, spart sich spätere Korrekturschleifen – und macht OneLake vom Risiko zum echten Wettbewerbsvorteil.
Langfristig ja. Microsoft positioniert das Fabric Warehouse und den Lakehouse-Ansatz als Nachfolger klassischer SQL-Warehouses. Bestehende T-SQL-Abfragen lassen sich weitgehend übernehmen, und durch den Direct Lake Modus entfällt die bisherige Import-Logik. Der Übergang kann schrittweise erfolgen – ein harter Schnitt ist nicht nötig.
Die Speicherung im OneLake ist vergleichsweise günstig. Bezahlt wird primär für die Rechenleistung – also die sogenannten F-SKUs (Fabric Capacity Units). Diese skalieren dynamisch mit der Nutzung. Unternehmen sollten den Verbrauch aktiv monitoren, da die Kosten bei intensiven Abfragen oder großen Spark-Jobs schnell steigen können.
Ja. Microsoft Azure ermöglicht die Festlegung der Datenresidenz auf europäische Regionen, beispielsweise Germany West Central (Frankfurt). Damit bleiben die Daten in Deutschland – ein entscheidender Faktor für Unternehmen mit strengen Compliance-Anforderungen.
Nicht zwingend. Analysten können mit gewohntem T-SQL arbeiten, und Dataflows Gen2 bieten eine visuelle Oberfläche für Transformationen. Für komplexere Szenarien – etwa Spark-basierte Datenverarbeitung oder automatisierte Pipelines – sind Python- oder PySpark-Kenntnisse jedoch von Vorteil.
Microsoft Fabric OneLake löst eines der hartnäckigsten Probleme in der Unternehmensdatenlandschaft: isolierte Datensilos. Durch die Kombination aus zentralem Speicher, offenem Datenformat und integriertem Lakehouse-Ansatz entsteht eine Plattform, die Reporting, Engineering und Warehousing erstmals in einer Umgebung zusammenführt.
Für Unternehmen, die bereits im Microsoft-Ökosystem arbeiten und unter fragmentierten Datenquellen leiden, ist Fabric eine strategisch sinnvolle Investition – vorausgesetzt, Governance und Kostenkontrolle werden von Anfang an mitgedacht.
Sie möchten wissen, ob Microsoft Fabric für Ihr Unternehmen der richtige Schritt ist? Als Spezialisten für Datenstrategie und Power BI im Raum München beraten wir Sie gerne – von der ersten Evaluierung bis zur produktiven Migration.