Power BI Git Versionierung mit PBIP und TMDL: Praxis Guide für Agentic BI Coding
Power BI Git Versionierung mit PBIP & TMDL für Agentic BI Coding & MCP: Repo-Struktur, Branching & CI/CD erklärt. TMSL-Falle bei Migration von PBIX vermeiden.

Power BI Git Versionierung mit PBIP & TMDL für Agentic BI Coding & MCP: Repo-Struktur, Branching & CI/CD erklärt. TMSL-Falle bei Migration von PBIX vermeiden.
Wer schon einmal versucht hat, mit zwei Entwicklern parallel an einer PBIX-Datei zu arbeiten, kennt das Spiel. Einer macht zu, der andere darf. Wer Pech hat, baut nach drei Stunden auf einem Stand auf, der inzwischen zweimal überschrieben wurde. Versionsstand vom Vormittag? Verloren. Rollback auf das funktionierende Measure von gestern? Geht nicht.
PBIX ist eine Binärdatei. Und Binärdateien und Git verstehen sich nicht. Warum? Wegen enormen Dateigrößen. Ein Github Repository ist zum Beispiel auf ca. 100 MB Maximalgröße begrenzt.
Microsoft hat dieses Problem inzwischen gelöst — mit zwei eher leisen, aber tief wirksamen Updates: dem PBIP-Format (Power BI Project) und der TMDL-Sprache (Tabular Model Definition Language). Zusammen machen sie aus Power-BI-Entwicklung das, was sie eigentlich sein sollte: ein normaler Software-Engineering-Workflow mit Branches, Pull Requests, Reviews und Deployment-Pipelines.
Dieser Artikel zeigt, wie du dein Team Schritt für Schritt dahin bringst — von der ersten PBIP-Datei bis zur automatisierten Auslieferung über Workspace-Git-Integration und Service Principal. Mit den Stolpersteinen, die uns selbst Stunden gekostet haben.
Die meisten Teams, die wir in Migrationsprojekten übernehmen, arbeiten noch wie 2020. PBIX-Dateien liegen in einem SharePoint-Ordner, jeder Entwickler zieht eine lokale Kopie, jemand pflegt eine Excel-Liste mit „wer arbeitet gerade an welchem Bericht". Wer parallel ändern will, wartet. Wer einen Fehler einbaut, hat keinen Weg zurück, der nicht bei jemandes lokaler Kopie endet.
Das hat zwei harte Konsequenzen:
Die erste ist fehlende Parallelarbeit . Drei KPIs, drei Entwickler. Jeder arbeitet an seinem KPI von Datenquelle bis Visualisierung. Ein realistisches Szenario in jedem ernsthaften Projekt — und mit PBIX praktisch unmöglich, weil die Datei eine binäre Blackbox ist. In der Praxis sehen wir Teams, die deswegen ihre Aufgaben nach Schichten aufteilen (einer macht Modellierung, einer macht Visualisierung, einer macht Datenaufbereitung). Das funktioniert in keinem realen Projekt sauber, weil Anforderungen quer durch alle Schichten laufen.
Die zweite ist fehlende Versionierung . Du hast morgens um zehn ein funktionierendes Measure gebaut. Nach zwei Stunden weiterer Änderungen merkst du, dass irgendwo ein Filterkontext kaputt ist. Welche der achtzehn Änderungen war es? Mit PBIX kannst du das praktisch nicht beantworten. Mit Git ist es ein Diff.
Wer in regulierten Branchen arbeitet — Versicherungen, Banken, Pharma — kennt eine dritte Konsequenz: fehlende Nachvollziehbarkeit . Jeder Audit fragt, wer wann was am Modell geändert hat. PBIX hat darauf keine Antwort. Git hat sie als Nebeneffekt.
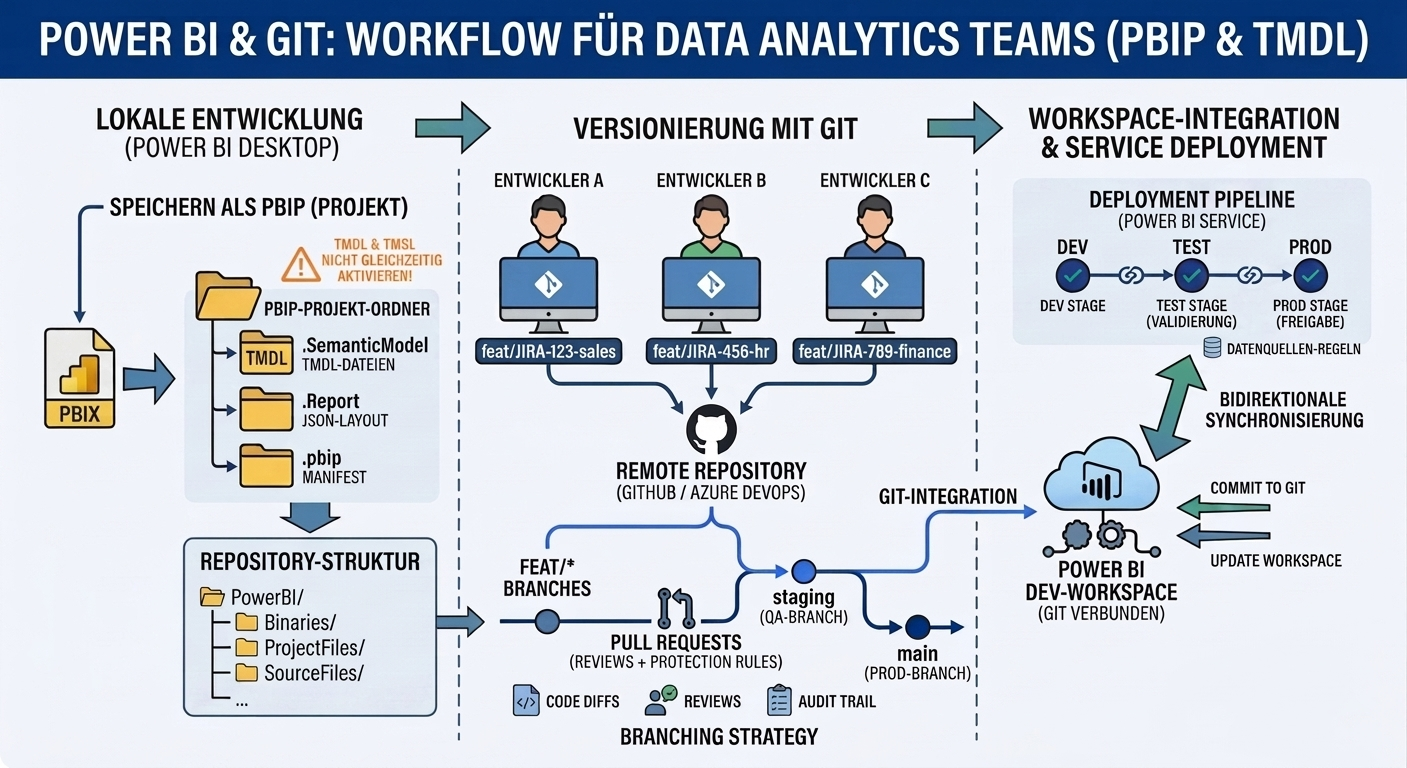
PBIP steht für Power BI Project . Statt einer einzigen PBIX-Datei legt Power BI Desktop einen Ordner an, der das Modell als strukturierte Sammlung kleiner Textdateien speichert. Konkret entstehen drei Dinge: eine .pbip -Datei (das Manifest), ein Ordner .Report (mit dem Layout im JSON-Format) und ein Ordner .SemanticModel (mit dem Datenmodell).
Die Trennung zwischen Report und SemanticModel ist strategisch. Sie spiegelt das, was im Power BI Service als Trennung zwischen Bericht und Dataset existiert. Wer sauber arbeitet, kann den Bericht versionieren, ohne das Modell anzufassen — und umgekehrt.
TMDL ist der zweite Teil der Geschichte. TMDL steht für Tabular Model Definition Language und ersetzt das alte TMSL-Format (Tabular Model Scripting Language), das XMLA-basiert war und in einer monolithischen model.bim -Datei lebte. TMDL ist textlastig, lesbar, und — das ist der entscheidende Punkt — pro Tabelle, pro Measure, pro Beziehung in einer eigenen Datei abgelegt. Das macht Diffs sinnvoll. Statt einer 40.000-Zeilen-JSON-Datei siehst du im Pull Request, dass genau ein Measure umbenannt wurde.
Beides zusammen — PBIP als Container, TMDL als Inhalt — ergibt erstmals ein Power-BI-Setup, in dem Git seine Arbeit macht.
Bevor wir in den Aufbau gehen, eine Stolperfalle, die in den Microsoft-Docs nicht prominent genug steht. Sie hat uns in einem Kundenprojekt einen halben Arbeitstag gekostet.
PBIP ist seit längerem ein Preview Feature in Power BI Desktop. TMDL ist es ebenfalls. In den Optionen findest du beide nebeneinander — und die intuitive Reaktion ist, beide zu aktivieren. Das ist der Fehler.
Wenn du beide aktivierst und eine PBIP-Datei aus einem Working Folder in dein Git-Repo kopierst, wirft Power BI beim nächsten Öffnen einen Fehler:
You cannot have both TMDL and TMSL formats in the same PBIP.
Offending file: ...\YOUR_MODEL.SemanticModel\model.bimWas passiert ist: Beide Formate werden parallel geschrieben. Sobald sowohl model.bim (TMSL) als auch .tmdl -Dateien (TMDL) im SemanticModel-Ordner liegen, weigert sich Power BI, die Datei zu öffnen. Das Modell ist nicht kaputt — aber unbenutzbar, bis du das Format-Problem auflöst.
Die Lösung ist banal: In den Power-BI-Optionen unter „Preview Features" darf nur der Haken bei „Power BI Project (.pbip) save option" gesetzt sein. Nicht zusätzlich „Store semantic model using TMDL format". Wer beide aktiviert, baut sich genau diesen Konflikt ein.
Praktischer Hinweis: Wenn du in einem laufenden Projekt schon TMDL aktiv hast und davon weg willst, lösche die .tmdl -Dateien manuell, behalte die model.bim . Wenn du umgekehrt von TMSL nach TMDL wechseln willst, lösche die model.bim und lass Power BI beim nächsten Speichern die TMDL-Struktur anlegen. Beide Dateitypen gleichzeitig im Repo — egal in welcher Reihenfolge — endet im selben Fehler.
Wir sehen in Projekten drei Reifegrade von Power-BI-Versionierung. Jeder hat seine Daseinsberechtigung. Wer Stufe 3 baut, ohne Stufe 1 verstanden zu haben, scheitert an der Adoption. Wer auf Stufe 1 stehen bleibt, obwohl das Team größer wird, scheitert an der Skalierung.
Wer alleine oder zu zweit an einem Bericht arbeitet, braucht keinen Git-Stack. Was er braucht, ist Rollback-Fähigkeit. SharePoint liefert die kostenlos: Jede Änderung an einer PBIX-Datei in einem SharePoint-Ordner erzeugt automatisch eine neue Version. Du kannst auf jeden vorherigen Stand zurück, du siehst, wer wann gespeichert hat.
Das ist kein „echtes" Versionsmanagement im Sinne von Branches und Diffs. Aber es ist der Unterschied zwischen „kann nicht zurück" und „kann zurück". In kleinen Teams ist das oft alles, was du brauchst.
Grenze dieser Stufe: Sobald zwei Entwickler gleichzeitig am selben Bericht arbeiten wollen, hilft SharePoint nicht mehr. Dann musst du auf Stufe 2.
Das ist der Kern dieses Artikels. PBIP-Format aktivieren, Repo aufsetzen, Branches bauen, Pull Requests einführen, Deployment Pipelines im Power BI Service zwischen DEV-, TEST- und PROD-Workspace nutzen.
Was du bekommst: Parallelarbeit, Code Reviews, Rollback auf Commit-Ebene, einen sauberen Audit-Trail über alle Änderungen, und eine klare Trennung zwischen „in Entwicklung", „in Test" und „in Produktion". Was du dafür investierst: einmaliges Setup von zwei bis drei Tagen, plus eine Lernkurve von einer bis zwei Wochen für ein Team, das vorher noch nicht mit Git gearbeitet hat.
Die meisten Mittelstandsteams sollten hier ankommen. Es ist die Stufe, ab der Power-BI-Entwicklung wie modernes Software-Engineering läuft, ohne dass du eine eigene DevOps-Engineering-Stelle dafür brauchst.
Stufe 3 setzt auf Stufe 2 auf und automatisiert das Deployment vollständig. Pull Request gemerged → GitHub Action oder Azure-DevOps-Pipeline läuft an → Service Principal authentifiziert sich gegen den Power BI Service → Bericht wird in den Ziel-Workspace deployed → automatisierte Tests laufen gegen das Dataset.
Diese Stufe lohnt sich, wenn du in mehreren Workspaces parallel ausrollst, wenn du regulatorische Anforderungen an Deployment-Trennung hast, oder wenn dein Team groß genug ist, dass manuelles Deployment ein eigener Engpass wird. Für ein Team von drei bis fünf Entwicklern reicht in der Regel Stufe 2.
Hier ist die Ordnerstruktur, die wir nach mehreren Projekten als praxistauglich etabliert haben. Sie unterscheidet bewusst zwischen Quellartefakten, Binärständen und Referenzmaterial — drei Dinge, die alle ins Repo gehören, aber unterschiedlich behandelt werden müssen.
project-root/
├── PowerBI/
│ ├── Binaries/ # Gezippte PBIX-Stände, getrennt nach Dataset und Report
│ ├── ProjectFiles/ # Die .pbip-Files samt .Report und .SemanticModel Ordner
│ ├── PaginatedReports/ # .rdl-Dateien für Paginated Reports
│ ├── Dataflows/ # Aus dem Service exportierte Dataflow-JSONs
│ ├── SourceFiles/ # Excel-Mappings, CSVs und andere Eingangsmaterialien
│ └── ReferenceFiles/ # Referenzwerte für QA, vom Kunden bereitgestellt
├── README.md
└── .gitignoreProjectFiles ist der Ordner, in dem die eigentliche Entwicklung passiert. Wenn du hier ein PBIP geöffnet hast, schreibt Power BI Desktop alle Änderungen in TMDL-Dateien, die Git als Textdiffs erkennt.
Binaries ist die zusätzliche Versicherung. Bei jedem produktiven Release legen wir den finalen PBIX-Stand zusätzlich gezippt ab, damit auch ohne PBIP-tauglichen Reader noch der originale Bericht reproduziert werden kann. Das ist Disziplin, die sich nach drei Jahren auszahlt.
SourceFiles und ReferenceFiles werden oft vergessen. SourceFiles sind die Excel-Mappings, CSV-Imports und Lookup-Tabellen, ohne die der Bericht nicht funktioniert. ReferenceFiles sind die Vergleichszahlen vom Kunden, die der QA-Manager zur Validierung braucht. Beide gehören ins Repo, weil sie integraler Bestandteil der Reproduzierbarkeit sind. Wer sie irgendwo auf einem Laufwerk liegen lässt, hat sie zwei Jahre später nicht mehr.
Die .gitignore ist kürzer, als man denkt. Sie schließt das .bundle -Cache-Verzeichnis aus (falls Asset Bundles im Spiel sind), Power-BI-eigene Cache-Dateien, und persönliche User-Settings. Was sie nicht ausschließt: irgendetwas im PBIP-Ordner. Das gehört alles ins Repo.
Hier kommt die kontraintuitive Entscheidung, an der viele Teams hängen bleiben. Die Frage lautet: Soll jeder Entwickler in einem eigenen Feature-Branch arbeiten, oder einigen sich alle auf einen gemeinsamen dev -Branch und pushen direkt dorthin?
Der gemeinsame dev -Branch sieht auf den ersten Blick einfacher aus. Weniger Branches, alle sehen denselben Stand, kein Hin und Her zwischen Branches. Genau das ist die Falle.
Ein gemeinsamer dev -Branch bedeutet: Wenn ein Entwickler einen Bug einbaut, ist er sofort für alle da. Der Branch wird über die Stunden „instabiler", weil immer jemand gerade in einem nicht-funktionierenden Zustand ist. Code Review wird zur Sammelaktion am Ende der Woche, in der niemand mehr nachvollziehen kann, welche Änderung von wem war. Merge-Konflikte beim Pull nach staging sind groß, kompliziert und betreffen alle.
Feature Branches drehen das Bild um. Jeder Entwickler arbeitet isoliert in einem eigenen Branch ( feat/JIRA-123-customer-segmentation ), öffnet nach Abschluss einen Pull Request gegen staging , der einzeln reviewt und einzeln gemerged wird. Pro PR sind die Änderungen klein, der Review ist machbar, der Merge-Konflikt — wenn er auftritt — ist auf einen Entwickler und ein Feature begrenzt.
Wir empfehlen Feature Branches in jedem Team mit mehr als zwei Entwicklern. Auch — gerade — wenn das Team Git noch nicht gut beherrscht. Der „einfachere" gemeinsame dev-Branch ist nur in den ersten zwei Wochen einfacher. Ab Woche drei ist er die Quelle der meisten Probleme.
In Branch-Namen Disziplin zu verlangen ist anstrengend, aber lohnenswert. Wir nutzen ein Schema wie feat/JIRA-123-kurze-beschreibung und setzen es per GitHub-Ruleset durch. Die zugehörige Regex sieht so aus:
^feat\/[A-Z]+-[0-9]+(-[a-zA-Z0-9-]+)*$Die Regex erlaubt: feat/PROJ-456-revenue-dashboard , feat/JIRA-123 ohne Beschreibung, feat/ABC-999-multi-step-feature . Sie verbietet: alles ohne feat/ -Prefix, lowercase Projekt-Codes, fehlende Ticket-Nummer, Unterstriche oder Leerzeichen in der Beschreibung.
Was du damit gewinnst: Jeder Branch ist sofort einem Ticket zuordenbar. Wer in zwei Jahren in das Repo schaut und einen Branch sieht, kann das zugehörige Jira-Ticket finden, ohne Archäologie zu betreiben.
Branch Protection — in GitHub als Rulesets, in Azure DevOps als Branch Policies — ist der Mechanismus, der durchsetzt, was deine Konvention vorschreibt. Ohne Branch Protection sind Konventionen Empfehlungen. Mit Branch Protection sind sie technisch erzwungen.
Wir setzen die Regeln gestaffelt nach Branch-Typ:
| Regel | main (Prod) | test (QA) | dev | feat/* |
|---|---|---|---|---|
| Pull Request erforderlich | Ja | Ja | Ja | Nein |
| Erforderliche Approvals | 2 | 1 | 1 | — |
| Stale Approvals verwerfen | Ja | Ja | Ja | — |
| Conversation Resolution | Ja | Ja | Ja | — |
| Force Push blockieren | Ja | Ja | Ja | Optional |
| Status Checks erforderlich | Ja | Ja | Ja | Nein |
| Branch-Naming-Regex | — | — | — | Ja |
Zwei Approvals für main ist kein Bürokratie-Reflex. Es ist die einzige zuverlässige Methode, zu verhindern, dass jemand am Freitagnachmittag um 17:00 einen Hotfix selbst freigibt, der am Montag den Bericht zerschießt. Bei einem oder zwei Reviewern wird Schluderei sichtbar. Bei null Reviewern wird sie zur Routine.
Stale Approvals verwerfen heißt: Wenn der PR neue Commits bekommt, wird die alte Genehmigung zurückgenommen. Reviewer müssen den finalen Stand explizit freigeben. Das verhindert, dass ein PR mit „looks good" approved wird, dann nochmal halbherzig umgebaut, und dann gemerged — ohne dass jemand den finalen Stand gesehen hat.
Die Branch-Naming-Regex auf feat/* ist optional, aber wer sie einmal aktiviert hat, will sie nicht mehr abgeben. Ein PR, der feature/myfix heißen will, lässt sich gar nicht erst erstellen.
Mit Repo, Branches und Reviews bist du auf der Code-Seite fertig. Was jetzt kommt, ist die Brücke vom Repository in den Power BI Service.
Microsoft hat Workspace-Git-Integration eingebaut, die im Power-BI-Workspace unter Settings → Git Integration zu finden ist. Du wählst zwischen Azure DevOps und GitHub, verbindest dein Repository, wählst den Branch und den Ordner, in dem deine PBIP-Files liegen — fertig. Änderungen, die in den verbundenen Branch gepusht werden, erscheinen automatisch im verbundenen Workspace.
Praktisch wichtig: Die Workspace-Git-Integration verbindest du mit dem DEV-Workspace , nicht mit Test oder Produktion. Das ist wichtig, weil die Integration bidirektional arbeitet: Änderungen im Workspace können auch zurück ins Repo committet werden. In TEST und PROD willst du das nicht, weil dort niemand „mal eben" am Bericht klicken soll. In DEV ist genau das der Punkt.
Den Weg von DEV nach TEST und PROD übernimmt eine Deployment Pipeline im Power BI Service. Drei Stages, jeweils einem Workspace zugeordnet. Wer auf Pipeline-Ebene deployed, schiebt den Bericht inklusive Dataset aus dem DEV-Workspace in den TEST-Workspace, und nach Validierung weiter in den PROD-Workspace. Datenquellen werden dabei pro Stage anders verbunden — DEV liest aus der DEV-Datenbank, PROD aus der Produktions-Datenbank.
In Stufe 3 ersetzt eine GitHub Action oder Azure-DevOps-Pipeline diesen manuellen Klick. Ein Service Principal — also ein nicht-personalisierter Anwendungsaccount, der gegen den Power BI Service authentifizieren darf — übernimmt das Deployment, sobald in staging oder main ein Merge passiert. Service Principals brauchen den Tenant-Setting-Schalter „Service principals can access the Power BI APIs" auf Tenant-Ebene plus eine Security Group, der der Principal angehört. Klingt kompliziert, ist es nicht — aber es muss vom Tenant-Admin freigeschaltet werden, was in vielen Konzernen der Engpass ist.
Ein letzter Punkt, der über reine DevOps-Hygiene hinausgeht. Wer mit KI-Agenten an Power-BI-Modellen arbeitet — wir tun das täglich, oft mit unserem Claude-basierten MCP-Setup — generiert in Stunden, was vorher Tage gedauert hat. Zwanzig Measures in dreißig Minuten. Komplette Staging-Tabellen aus einer Excel-Quelle in einer Stunde. Beziehungen, Kalender-Tabellen, Sortier-Spalten — alles automatisch.
Das ist großartig, solange es funktioniert. Es ist katastrophal, wenn ein KI-Agent in einer Session etwas verändert, was er in der nächsten Session nicht reproduzieren kann. Ohne Versionierung suchst du dann nach einem Stand, den du dir nicht gemerkt hast.
Aus unserem aktuellesten Whitepaper zu Agentic BI Workflows — der Satz ist kompromisslos formuliert, weil er kompromisslos gemeint ist:
KI-gestützte Entwicklung ohne Versionierung ist russisches Roulette. Punkt. Du wirst Zustände im Modell produzieren, die du zurückdrehen musst. Du wirst Entscheidungen treffen, die du im Zweifel nachvollziehen können musst. Du wirst Diffs zwischen zwei Versionen brauchen, um zu verstehen, was sich zwischen Session 3 und Session 7 eigentlich geändert hat.
Versionierung ist nicht das Sahnehäubchen auf einem KI-gestützten Workflow. Sie ist die Voraussetzung dafür, dass dieser Workflow überhaupt seriös sein kann. Genau aus diesem Grund stehen PBIP, TMDL und Git in jedem unserer Migrationsprojekte vor jedem Einsatz von KI-Agenten — nicht danach.
Bevor du loslegst, eine Liste von Fehlern, die wir bei uns selbst und bei Kunden gesehen haben. Jeder davon kostet zwischen einem halben Tag und einer Woche, je nachdem, wie spät er auffällt.
Beide Preview Features gleichzeitig aktiviert. Der oben beschriebene TMDL/TMSL-Konflikt. Nur PBIP aktivieren, TMDL erst dann zuschalten, wenn das Projekt komplett auf TMDL umgestellt ist.
Keine .gitignore für SourceFiles und Caches. Vertrauliche Excel-Quellen, Power-BI-Cache-Verzeichnisse und persönliche User-Settings landen sonst im Repo. Erst wenn jemand ein verteiltes Repo durchforstet, fällt das auf.
Direkt-Pushes auf main erlaubt. Ohne Branch Protection kann jeder Entwickler — auch versehentlich — direkt auf den Produktiv-Branch committen. Das ist in einem Audit nicht erklärbar.
Keine Service Principals für PROD-Deployments. Wer sein Produktiv-Deployment an den persönlichen Account eines einzelnen Entwicklers koppelt, hat ein Problem, sobald derjenige im Urlaub ist oder das Unternehmen verlässt. Service Principal einrichten, einmal, ordentlich.
Workspace-Git-Integration im falschen Workspace. Die Integration gehört in DEV, nicht in TEST oder PROD. Wer sie in PROD aktiviert, ermöglicht ungewollte Rückkanäle vom Klickbedienenden ins Repo.
Wenn du dieses Setup für dein Team aufbauen willst, hier die erste Stunde, die wirklich zählt:
Öffne Power BI Desktop, geh in Optionen → Vorschaufunktionen und setze nur den Haken bei „Power BI Project (.pbip) save option". TMDL bleibt aus, bis du das ganze Projekt darauf migriert hast. Speichere danach einen bestehenden Bericht als PBIP — du siehst sofort die Ordnerstruktur entstehen.
Leg ein Repository an (Azure DevOps oder GitHub, beides funktioniert) mit den Branches main , staging , und dev . Setze auf main zwei Pflicht-Approvals und Force-Push-Schutz. Auf staging einen. Auf dev einen. feat/* lässt du frei.
Klone das Repository lokal, leg den PBIP-Ordner hinein, mache deinen ersten Commit. Push, öffne einen Pull Request gegen dev , verschmelze ihn. Du hast gerade eine Power-BI-Entwicklung mit Source Control gemacht.
Das ist der Mindeststand für ein produktives Setup. Alles weitere — Workspace-Git-Integration, Deployment Pipelines, CI/CD, Service Principals — ist Zusatzarbeit, die sich aufbaut, ohne dass du das Fundament neu legen musst.
Wir machen genau das in unseren Power-BI-Migrationsprojekten — von der Excel-Wildwuchs-Realität zu einem versionierten, reviewbaren, auditierbaren Power-BI-Bestand, der modernem Software-Engineering entspricht. Wenn du dafür eine Außensicht oder eine konkrete Bestandsaufnahme deines aktuellen Setups brauchst, kommen wir gern für eine ehrliche 30-Minuten-Einschätzung ins Gespräch.
Wer lieber selbst startet: Microsofts PBIP-Dokumentation ist solide, und unsere weiteren Praxisartikel zu Sternschema-Modellierung und MCP-Server-Setups decken die nächsten zwei Schritte ab, die typischerweise nach dem Versionierungs-Setup kommen.
Was du dir mitnehmen solltest: Power BI Git Versionierung mit PBIP und TMDL ist 2026 kein Nice-to-Have mehr, sondern die Basis, auf der jede ernsthafte Power-BI-Entwicklung steht. Die Werkzeuge sind da, die Best Practices stehen — was bleibt, ist die Disziplin, sie konsequent zu nutzen.