SAS nach Oracle mit künstlicher Intelligenz ohne Halluzination migrieren
SAS zu Oracle automatisiert ohne KI-Halluzinationen migrieren: Wissensgraph statt Blindflug. Valides SQL genrieren 100% Lineage geprüft.

SAS zu Oracle automatisiert ohne KI-Halluzinationen migrieren: Wissensgraph statt Blindflug. Valides SQL genrieren 100% Lineage geprüft.
Eine über Jahre gewachsene SAS-Landschaft fühlt sich an wie eine Black Box: Die Berichte laufen, aber niemand weiß mehr genau, welche Logik in welchem Schritt steckt — und die Lizenzkosten laufen jedes Jahr weiter. Generative KI verspricht die schnelle Befreiung. Doch ohne strukturelle Vorarbeit wird genau diese KI zum Risiko: Sie erfindet Geschäftslogik, statt sie zu übersetzen.
Executive Summary: Der strategische Business Case der SAS-Ablösung
Daten sind das Fundament für moderne Geschäftsmodelle und KI-Initiativen — doch in vielen Unternehmen steckt die wichtigste Geschäftslogik in jahrzehntealten, proprietären SAS-Skripten fest. Diese gewachsenen Strukturen sind heute ein massiver Flaschenhals: teuer, schwer wartbar und für moderne Cloud-Datenbanken unzugänglich.
Eine Migration von SAS zu einem offenen Standard wie Oracle-SQL ist daher kein reines IT-Wartungsprojekt, sondern ein strategischer Befreiungsschlag : Sie löst den Vendor Lock-in und macht Daten unternehmensweit nutzbar. Bisher scheiterten solche Vorhaben am personellen Aufwand der manuellen Umschreibung. Generische KI-Tools (Standard-ChatGPT & Co.) scheinen die Lösung — führen bei komplexen Legacy-Systemen aber unweigerlich zu gefährlichen Halluzinationen : Die KI erfindet Geschäftslogik, weil sie die tiefen Code-Abhängigkeiten nicht überblickt.
Der ABIS-Ansatz nutzt KI grundlegend anders: Er kartografiert die SAS-Logik zuerst als Wissensgraphen und lässt die KI erst danach übersetzen. Das eliminiert Halluzinationen und garantiert eine auditierbare Transformation. Vier Hebel für das Management:
Beschleunigte Time-to-Market: Black-Box-Logik wird zu sauberem SQL, das jeder moderne Analyst liest — neue Reports entstehen drastisch schneller. Maximierung des Talent-ROI: Knappe Spezialisten warten nicht länger Legacy-Code, sondern bauen Cloud, Self-Service-BI und Advanced Analytics. Zukunftssicherheit: Das SQL befreit von proprietären Lizenzen — heute Oracle, morgen bereit für Fabric, Snowflake oder Databricks. Compliance & Risiko: Das Key-Person-Risiko entfällt; eine zu 100 % dokumentierte Lineage macht jeden Datenpunkt auditierbar — essenziell für regulierte Branchen.
Für die Geschäftsführung ist SAS selten ein Technik-, sondern ein Strategiethema . Drei betriebswirtschaftliche Risiken stehen im Vordergrund:
Doppel-Lizenz-Falle. Viele Unternehmen ziehen Daten aus Oracle, transformieren sie in SAS und spielen sie zurück — und zahlen für beide Systeme. Die SAS-Schicht ist oft reine Mittelschicht, die sich eliminieren lässt.
Key-Person-Risiko. Die Fachlogik ist nur mit aktiver SAS-Lizenz und seltenem Spezialwissen les- und wartbar. Geht der eine Veteran in Rente, geht das Geschäftswissen mit.
Innovationsstau. Solange die wichtigste Logik in einer Black Box gefangen ist, lässt sie sich nicht für Cloud-Plattformen, Self-Service-BI oder KI-Initiativen nutzen. Das blockiert die Datenstrategie an der Wurzel.
Die Migration zu offenem SQL adressiert alle drei zugleich. Die Frage war nie ob , sondern wie ohne Risiko und ohne ein Team über Monate zu binden .
Mit generativer KI scheint die Antwort auf der Hand zu liegen: Code rein, SQL raus. In der Praxis ist das bei komplexem Legacy-Code ein Blindflug .
Warum ChatGPT & Copilot bei SAS halluzinieren: Generische KIs lesen Code als flachen Text. Besteht ein SAS-Job aus 44PROC SQL-Blöcken und greift auf flüchtigework-Tabellen zu, verliert ein Standard-LLM im Kontextfenster den Faden. Die KI rät die fehlenden Abhängigkeiten und erzeugt SQL, das syntaktisch korrekt aussieht, aber die Geschäftslogik zerstört. Ohne den ABIS-Wissensgraphen, der die Struktur vorher mappt, ist KI-Übersetzung ein Blindflug.
Das Tückische: Der Fehler ist unsichtbar . Halluziniertes SQL läuft fehlerfrei durch, liefert plausible Zahlen — und ist trotzdem falsch. Solche Fehler fallen erst Monate später im Produktivbetrieb auf, wenn eine Kennzahl nicht mehr stimmt und niemand weiß, warum. Für einen Blutspendedienst oder eine regulierte Branche ist das nicht hinnehmbar.
Konkret scheitert der reine Chatbot-Ansatz an drei strukturellen Grenzen:
Kontextfenster. Die vollständige Abhängigkeitskette dutzender Blöcke über mehrere Schemas passt nicht zuverlässig gleichzeitig in ein Modell-Fenster. Das Modell sieht Ziegel, nicht die Statik.
Unsichtbare Logik. Bezieht sich ein Schritt auf eine flüchtige work -Tabelle aus einem anderen, nicht mit eingefügten Job, wird der sichtbare Teil korrekt übersetzt — und die Abhängigkeit still übersehen.
Keine Wiederholbarkeit. Eine Ad-hoc-Sitzung produziert SQL, aber keine versionierbare Herkunftskette. „Die KI hat das mal übersetzt" ist nicht auditierbar — und bei Bericht Nr. 2 beginnt man wieder bei null.
ABIS-Migrationsansatz: eine Methodik, die Legacy-SAS-Code zuerst in einen semantischen Wissensgraphen überführt, bevor KI angewendet wird — und damit die Halluzinationsrisiken generischer LLMs vollständig eliminiert.
Der entscheidende Unterschied: Der SAS-Code wird nicht durchsucht, sondern als Graph erschlossen. Jeder PROC-SQL-Block, jeder DATA -Step und jede Tabelle wird ein Knoten , jede Datenabhängigkeit eine Kante .
MCP ist dabei wie der USB-C-Standard für KI: eine einheitliche Schnittstelle, über die ein KI-Agent jeden Knoten des Graphen ansteuern kann, ohne für jede Datenquelle eine eigene Anbindung zu brauchen.
Eine KI traversiert diesen Graphen über das Model Context Protocol (MCP) , rekonstruiert die vollständige Ausführungskette und generiert daraus direkt deploybares Oracle-SQL — mit Quell-Referenz im Header. Was vorher nur ein SAS-Editor lesen konnte, wird navigierbar, filterbar und maschinenlesbar. Die KI rät nicht mehr; sie liest präzise den gemappten Kontext.
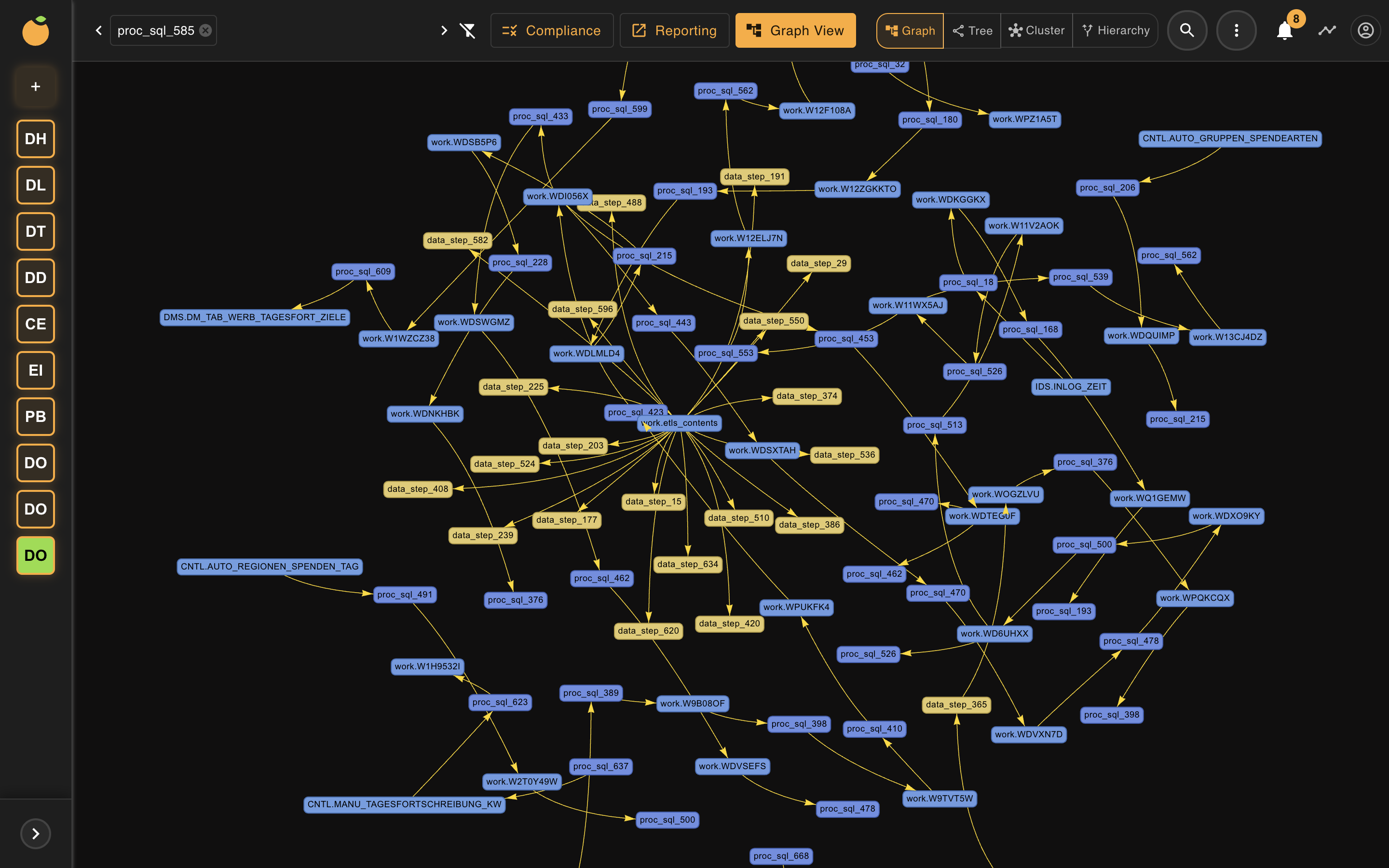
Der Öffentlicher-Blutspendedienst betreibt sein gesamtes Tagesreporting über einen proprietären SAS-Stack auf einem Oracle-Datenbestand. Rund 100 Berichte hängen an dieser Pipeline. Die interne Schicht- und Tabellenstruktur ist hier anonymisiert; die Verarbeitungslogik ist unverändert wiedergegeben.
| Schicht | Rolle | Charakter |
|---|---|---|
| Oracle-Quelle (Z-Layer) | Quelle der Wahrheit | Vollständiger Datenbestand, täglich beladen |
| Schicht 1 — Eingang | 1:1-Übernahme | Ungefilterter Direktabzug aus Oracle + CSV |
| Schicht 2 — Zusammenführung | leichte Transformation | Regionen-Merge, Mappings über Steuertabellen |
| Schicht 3 — Logik-Mart | Kernlogik | Die eigentliche Geschäftslogik — undokumentiert |
| Berichte (.sas) | Auslieferung | Greifen direkt auf die Mart-Tabellen zu |
Die ersten beiden Schichten transportieren und vereinheitlichen nur. Die dritte Schicht trägt die gesamte fachliche Komplexität — und ist zugleich am schlechtesten dokumentiert. Genau dort entsteht das Migrationsrisiko.
Stellvertretend wurde ein Bericht analysiert, der Wochen-Ist-Werte, Prognosen und Zielvorgaben nach Region und Spendentyp zusammenführt. Klingt überschaubar. Die SAS-Realität:
| Kennzahl | Umfang | Bedeutung |
|---|---|---|
| 44 | PROC-SQL-Blöcke | seriell, ohne Dokumentation |
| 25 | DATA-Steps | einer davon: manueller Unpivot über 9 Regionsspalten |
| 16 | flüchtige Arbeitstabellen | verschwinden nach Job-Ende spurlos |
| 7 | Quell-Entitäten | aus 3 verschiedenen Schemas |
Versteckt in einem der Blöcke: ein Jahr-über-Jahr-Self-Join (laufendes Jahr gegen Vorjahr). Nichts davon war dokumentiert — genau die Sorte Logik, die eine generische KI stillschweigend übersehen würde.
Aus diesem einen Bericht entstand ein Graph mit 111 Knoten und 97 Kanten über 3 Schemas . Die KI-Sitzung lieferte:
| Zeilen SQL | Sitzung | Views, deploybar | Lineage |
|---|---|---|---|
| 457 | < 1 h | 4 | 100 % |
Das ist kein Proof-of-Concept, der noch „industrialisiert" werden müsste, sondern deploybarer Code gegen Oracle 19c.
Ehrlich gesagt: Der erste Wurf flog raus. Version 1 bestand aus 23 ineinander gestapelten Views — technisch korrekt, operativ Unsinn. Auf Kundenwunsch sofort verworfen. Version 2 faltet die Logik pro Ziel-View in einen einzigen WITH -Block. Genau dafür ist der Mensch im Loop da.Klassische Migrationen werden über Lizenzkosten verkauft. Das greift zu kurz. Der wahre Kostentreiber ist die Personenzeit hochspezialisierter Entwickler. Wer ihre Tage von der defensiven Beseitigung technischer Schuld auf wertschöpfende Projekte umlenkt, hebt einen weit größeren Wert als die reine Lizenzersparnis.
| Arbeitsschritt | Klassisch (manuell) | Mit ABIS + KI |
|---|---|---|
| SAS-Code lesen & verstehen | 3–5 Tage | 0 — Graph-Extraktion |
| Datenfluss dokumentieren | 2–3 Tage | 0 — Graph ist die Doku |
| SQL schreiben & testen | 5–8 Tage | ~0,5 Tage Review + Tests |
| SAS-Funktionen übersetzen | 1–2 Tage | 0 — automatisch |
| QS & Peer Review | 2–3 Tage | 1 Tag — bleibt bewusst drin |
| Gesamt pro Report-Gruppe | 13–21 Tage | 1,5–2 Tage |
Der Scope ist präzise: Analyse und Übersetzung einer Report-Gruppe — nicht das Gesamtprojekt. Deshalb sprechen wir bewusst von Faktor ~10, nicht von mehr.
Ein Mittelständler mit ~250 Mitarbeitern arbeitet typischerweise nicht mit einem 20-köpfigen SAS-Team, sondern mit 3–5 SAS-Entwicklern bzw. Power-Usern . Auf diese Größenordnung gerechnet:
| Status Quo — SAS, laufender Betrieb | Betrag/Jahr |
|---|---|
| SAS Base + Analytics (4 User) | ~30.000 € |
| SAS/ACCESS to Oracle (Server-Lizenz) | ~20.000 € |
| SAS-Server-Infrastruktur (Wartung & Compute) | ~12.000 € |
| Laufende SAS-Kosten p. a. | ~62.000 € |
| Über 3 Jahre | ~186.000 € |
| Zielbild — Oracle-Migration | Betrag |
|---|---|
| Migrationsprojekt (KI-gestützt, Jahr 1, einmalig) | ~55.000 € |
| Inkrementelle Oracle-Infrastruktur p. a. | ~5.000 € |
| 3-Jahres-Kosten (55.000 + 5.000 + 5.000) | ~65.000 € |
Reine TCO-Einsparung nach 3 Jahren: ~121.000 € (≈ 65 %) — allein auf Lizenz- und Infrastrukturebene. Der größere Hebel sind die freigesetzten Spezialisten-Tage: Ein Lead-Architekt steuert die Konvertierung, die übrigen Spezialisten arbeiten ab Tag 1 an wertschöpfenden Projekten. Niemand wird entlassen — in Zeiten des Fachkräftemangels wäre das falsch. Der Gewinn ist die Umlenkung knapper Kapazität.
Gut zu wissen: Die Lizenz- und Personalzahlen sind ein illustratives Branchenmodell zur Einordnung der Größenordnung für einen Mittelständler mit ~250 Mitarbeitern. Sie ersetzen keine projektspezifische TCO-Rechnung. Belastbar gemessen sind dagegen die Discovery-Case-Zahlen: Faktor ~10, 457 Zeilen, < 1 Stunde.
Die KI ersetzt SAS-Konstrukte nicht eins zu eins, sondern überführt sie in die idiomatische, performante Oracle-Entsprechung:
| SAS (vorher) | Oracle (nachher) | Charakter |
|---|---|---|
YEAR(DATE()) | EXTRACT(YEAR FROM SYSDATE) | direkte Entsprechung |
CASE WHEN x eq . THEN 0 | NVL(x, 0) | Null-Behandlung (. = missing) |
DATA-Step Wide→Long (multi-OUTPUT) | UNPIVOT + REGEXP_SUBSTR | höchster Übersetzungsaufwand |
UPDATE + PROC APPEND | MERGE INTO … ON (DAY_CODE) | inkrementeller Upsert |
16 flüchtige work.WXXX-Tabellen | 16 CTEs (oder GTTs bei großen Plänen) | Zwischenstufen aufgelöst |
FULL JOIN + CASE WHEN key eq . | FULL OUTER JOIN + COALESCE(...) | null-sicherer Schlüssel |
PUT(DAY_CODE, BEST32.) | TO_CHAR(DAY_CODE) | Numerik → String |
3× CREATE TABLE | 3× CREATE OR REPLACE VIEW | deploybare Zielobjekte |
Ein konkretes Beispiel — der inkrementelle Upsert. SAS löst das zweistufig (Update bestehender Zeilen, dann Append neuer Zeilen):
/* SAS (vorher): zweistufiges Muster aus SAS DI Studio */
PROC SQL;
UPDATE ziel z
SET wert = (SELECT s.wert FROM staging s WHERE s.day_code = z.day_code)
WHERE EXISTS (SELECT 1 FROM staging s WHERE s.day_code = z.day_code);
QUIT;
DATA etls_newrecords;
/* Zeilen, die im Ziel noch nicht existieren ... */
RUN;
PROC APPEND BASE=ziel DATA=etls_newrecords; RUN;-- Oracle (nachher): ein einziges MERGE, Lineage-Kommentar im Header
-- Migrated from: Schicht1_Planzahlen_SAS · Generated by: DBI Analytics GmbH · 2026
MERGE INTO ziel z
USING staging s
ON (z.day_code = s.day_code)
WHEN MATCHED THEN UPDATE SET z.wert = s.wert
WHEN NOT MATCHED THEN INSERT (day_code, wert) VALUES (s.day_code, s.wert);Aus zwei prozeduralen Schritten plus flüchtiger Zwischentabelle wird eine einzige, deklarative MERGE -Anweisung, die der Optimizer als Ganzes plant. Die Herkunft steht als Kommentar direkt im Code — die Lineage lebt im SQL, nicht in einer Folie daneben.
Eine seriöse Bewertung benennt auch die schwierigen Stellen. Vier Punkte, die ein erfahrener IT-Leiter zu Recht hinterfragt — und unsere offene Antwort darauf:
SAS-Makros (dynamischer Code). SAS generiert per %MACRO und &var. Code zur Laufzeit. Ein rein statischer Parser kann diese Logik nicht vollständig auflösen. Der Discovery Case prüft deshalb gezielt die Makro-Tiefe Ihrer Codebasis: Makros werden expandiert und als aufgelöste Knoten in den Graphen aufgenommen, bevor übersetzt wird. Bleibt etwas dynamisch nicht auflösbar, wird es explizit markiert — nicht geraten.
Die Mega-CTE-Performance-Falle. Ein einziger riesiger WITH -Block kann den Oracle-Optimizer (CBO) überfordern und zu schlechten Plänen und hohem TEMP -Verbrauch führen. Die elegante Git-Ansicht ist nicht automatisch der schnellste Plan. Für große Pipelines sind Global Temporary Tables (GTTs) oder bewusst materialisierte Zwischenstufen oft die bessere Wahl. Genau deshalb bleibt die Architektur-Entscheidung beim Menschen — wie das verworfene 23-View-Beispiel zeigt.
„Vendor-agnostisch" ist relativ. Oracle-SQL ist proprietär: NVL , SYSDATE , VARCHAR2 und Oracles MERGE -Syntax portieren nicht 1:1 nach Snowflake ( COALESCE , CURRENT_DATE , VARCHAR ) oder Fabric. Der ehrliche Anspruch lautet daher: SAS zu verlassen befreit von der teuersten Lizenz; der Schritt zu Snowflake/Fabric ist eine zweite , aber deutlich leichtere Übersetzung — weil die Logik dann bereits als sauberer, dokumentierter Graph vorliegt.
Komplexe statistische und Transpose-PROCs. PROC SUMMARY / PROC MEANS lassen sich gut auf Aggregat-SQL abbilden. Mehrschichtige PROC TRANSPOSE mit BY - und ID -Statements sowie echte Statistik-Prozeduren ( PROC REG , PROC FORECAST ) haben keine saubere Einzeiler-Entsprechung in der Datenbank — sie werden bewusst kenntlich gemacht und umgeleitet, statt halluziniert zu werden.
Dieser Realismus ist kein Schwächezeichen, sondern der Grund, warum der Einstieg ein strikt begrenzter Discovery Case ist: Er beweist die Makro- und Transpose-Fähigkeit an Ihrem Code, bevor Sie investieren.
Drei Gründe sprechen gegen Abwarten:
Der Fachkräftemangel verschärft sich. Jedes Jahr, das SAS-Veteranen näher an die Rente rücken, erhöht das Key-Person-Risiko. Das Wissen jetzt in einen Graphen zu sichern, ist eine Versicherung gegen seinen Verlust.
KI-Initiativen brauchen offene Daten. Solange die Kernlogik in SAS gefangen ist, bleibt jede Cloud- und KI-Strategie auf halber Strecke stehen. Die Migration ist die Voraussetzung, nicht der Nachgedanke.
Der erste Schritt ist klein und risikoarm. Ein einzelner SAS-Job als Discovery Case liefert Ihre vollständige Lineage und eine belastbare Aufwandsschätzung — in Tagen, bevor Sie irgendetwas entscheiden.
Eine SAS-zu-Oracle-Migration ist kein reines Übersetzungsproblem — sie ist ein Sichtbarkeitsproblem . Wer den Code nur als Text liest (ob von Hand oder mit generischer KI), übersieht versteckte Logik und produziert teure, unsichtbare Fehler. Wer ihn als Wissensgraph erschließt, macht die vollständige Lineage zum Nebenprodukt und lässt eine KI daraus produktionsreifes, auditierbares SQL erzeugen — review-fertig in einem Bruchteil der Zeit.
Für die Geschäftsführung ist die Rechnung eindeutig: weg vom Vendor Lock-in, weg vom Key-Person-Risiko, hin zu Cloud- und KI-Readiness — und das bei einer Amortisation, die sich schon auf Lizenzebene meist in 12–18 Monaten einstellt. Der naheliegende nächste Schritt ist klein: ein einzelner SAS-Job als Discovery Case. Sprechen Sie mit unseren BI-Migrationsexperten über einen Discovery Case für Ihre SAS-Landschaft.
Nein. Generische KI wird halluzinieren. Standard-Modelle verarbeiten Code als Text und können mehrstufige SAS-Abhängigkeiten oder flüchtige work -Tabellen nicht im Kontextfenster halten. Das Ergebnis sieht syntaktisch korrekt aus, zerstört aber die Geschäftslogik — und der Fehler fällt erst Monate später auf. Sie müssen zuerst einen Wissensgraphen (wie ABIS) nutzen, der die Abhängigkeiten mappt, sonst erfindet die KI die fehlende Logik.
Durch einen vorgeschalteten Wissensgraphen. Bevor die KI auch nur eine Zeile SQL schreibt, analysiert das System den SAS-Code und baut ein strukturiertes Netzwerk aus Knoten (Blöcke, Steps, Tabellen) und Kanten (Datenabhängigkeiten) auf. Die KI übersetzt dann nicht blind Text, sondern navigiert deterministisch durch diesen Graphen über MCP — sie liest präzisen, gescopten Kontext statt zu raten. Genau das ist der Unterschied zwischen einer auditierbaren Übersetzung und einem Blindflug.
Makros werden vor dem Graph-Aufbau expandiert und als aufgelöste Knoten aufgenommen, sodass auch zur Laufzeit erzeugte Tabellen- und Spaltenstrukturen sichtbar werden. Wo etwas dynamisch nicht vollständig auflösbar ist, wird es explizit markiert statt geraten. Die Makro-Tiefe Ihrer konkreten Codebasis zu prüfen, ist ein zentraler Zweck des Discovery Case.
Es kann eines sein. Ein überdimensionierter WITH -Block kann den Cost-Based Optimizer überfordern. Deshalb ist die Architektur-Entscheidung bewusst menschlich: Je nach Pipeline werden gefaltete CTEs, materialisierte Zwischenstufen oder Global Temporary Tables (GTTs) gewählt. Elegant in Git ist nicht automatisch schnell im Betrieb.
Teilweise. Das SQL verlässt die teure SAS-Lizenz und läuft nativ auf Oracle 19c. Oracle-SQL ist jedoch proprietär; ein späterer Wechsel zu Snowflake oder Fabric erfordert eine zweite Übersetzung. Diese ist aber deutlich leichter, weil die Logik dann als sauberer, dokumentierter Graph vorliegt — nicht mehr als SAS-Black-Box.
Nein — und das ist nachweisbar. Weil der Code als Wissensgraph erschlossen wird, sieht die KI die vollständige Ausführungskette inklusive versteckter Konstrukte wie Jahr-über-Jahr-Self-Joins. Jeder generierte CTE referenziert seinen SAS-Ursprungsschritt als Kommentar, sodass die Lineage im Code auditierbar bleibt. Das menschliche Review ist fester Bestandteil des Prozesses.
Er bezieht sich präzise auf Analyse und Übersetzung einer Report-Gruppe — nicht auf das Gesamtprojekt — und stammt aus dem real durchgeführten Discovery Case (13–21 Tage klassisch gegen 1,5–2 Tage mit ABIS). Wir kommunizieren bewusst Faktor ~10 und nicht mehr.
Nein. Teil des Vorgehens ist, gemeinsam zu prüfen, welche Berichte noch zeitgemäß sind und welche Logiken sich zusammenfassen oder auf die Oracle-Datenbank zurückbauen lassen. Die Migration wird so zur Gelegenheit, die Reportinglandschaft zu verschlanken.
Nächster Schritt: Starten Sie nicht mit einem Big-Bang-Projekt. Fordern Sie einen Discovery Case für einen einzelnen kritischen SAS-Job an — so validieren Sie Graph-Extraktion, Makro-Auflösung und die Qualität des generierten SQL risikolos auf Ihren eigenen Daten, bevor Sie über das Gesamtprojekt entscheiden.
Quellen & Weiterführendes: SAS→Oracle Translation Playbook (DBI Analytics, 2026); Discovery Case Öffentlicher-Blutspendedienst. Alle Lizenz- und Personalbeträge sind geschätzte Branchenwerte zur Budgetierung und variieren je nach Vertrag, Region und Teamgröße.